Currículo: esta unidad cubre todos los contenidos del Bloque 3 – Datos masivos, ciberseguridad e inteligencia artificial correspondiente a 1ºESO. Además, se evalúan los criterios 3.1 (Conocer la naturaleza de las distintas tipologías de datos siendo conscientes de la cantidad de datos generados hoy en día; analizarlos, visualizarlos y compararlos), 3.2 (Comprender y utilizar el periodismo de datos) y 3.3 (Entender y distinguir los dispositivos de una ciudad inteligente).
Este documento forma parte de los contenidos curriculares del curso 2022/2023. Al finalizar ese curso la administración autonómica andaluza, modificó el currículum de esta asignatura, por lo que se encuentra desactualizado. Los contenidos vigentes desde el curso 2023/24 son los que puedes encontrar en Tema 7. Datos masivos.
Tabla de contenidos
- 5.1. Big Data
- 5.1.2. Volumen de datos generados
- 5.2. Visualización, transporte y almacenaje de los datos
- 5.3. Recogida y análisis de datos
- 5.4. Generación de nuevos datos
- 5.5. Entrada y salida de datos de los dispositivos y las apps
- 5.6. Periodismo de datos
- 5.7. Data scraping
5.1. Big Data
Bienvenidos al tema de Big Data, también conocido como Datos Masivos. A lo largo de este tema, aprenderemos qué es el Big Data, sus características y cómo se generan y procesan grandes volúmenes de datos.
El término “Big Data” se refiere al conjunto de datos tan grande, rápido y complejo que es difícil procesarlos utilizando métodos tradicionales. A medida que la tecnología avanza, la cantidad de datos que creamos y compartimos cada día también crece. Desde mensajes en redes sociales hasta registros de compras y datos meteorológicos, todo forma parte del Big Data.

5.1.1. Características
El Big Data se caracteriza principalmente por las 5 V’s:
- Volumen: La cantidad de datos generados y almacenados es muy grande y continúa creciendo.
- Velocidad: Los datos se generan y deben ser procesados rápidamente para tomar decisiones en tiempo real.
- Variedad: Los datos provienen de diversas fuentes y en diferentes formatos, como texto, imágenes, videos, etc.
- Veracidad: La calidad y precisión de los datos es importante, ya que los datos erróneos pueden afectar el análisis y las decisiones.
- Valor: Los datos deben ser útiles y proporcionar información valiosa para la toma de decisiones.
Ejemplo del mundo real – INSTAGRAM
Imagina que estás en una red social como Instagram.
- Volumen: Cada día, millones de personas alrededor del mundo suben fotos y vídeos a Instagram. Esto significa que se generan grandes cantidades de datos. El volumen de datos en Instagram es enorme y sigue creciendo cada día.
- Velocidad: Cuando suben una foto o un vídeo a Instagram, esta información se difunde rápidamente a través de la red a sus seguidores y a otras personas que pueden encontrar su contenido. La velocidad con la que se generan y se transmiten estos datos es realmente impresionante.
- Variedad: En Instagram, no solo se comparten fotos y vídeos, también se pueden encontrar comentarios, “me gusta”, etiquetas, mensajes directos y mucho más. Esto significa que hay una gran variedad de tipos de datos en la plataforma.
- Veracidad: Aunque la mayoría de las personas comparten fotos y vídeos reales en Instagram, a veces algunas personas pueden subir contenido falso o manipulado. La veracidad se refiere a la calidad y exactitud de los datos. Es importante ser capaces de distinguir entre datos verdaderos y falsos.
- Valor: Aunque hay millones de datos en Instagram, no todos ellos son útiles o relevantes para todos. El valor se refiere a la importancia o utilidad de los datos para un propósito específico. Por ejemplo, una empresa que vende ropa deportiva puede encontrar valor en los datos de las personas que siguen a influencers del fitness, ya que podrían ser clientes potenciales.
5.1.2. Volumen de datos generados
Cada día generamos una enorme cantidad de datos. Según estudios, en 2021 se generaban 2,5 quintillones de bytes de datos diariamente en todo el mundo. Esta cantidad seguirá aumentando a medida que más personas accedan a Internet y usen dispositivos electrónicos.
Los datos se generan en diferentes formas: mensajes en redes sociales, búsquedas en Internet, compras online, uso de aplicaciones móviles, entre otros. La mayoría de estos datos son generados por los usuarios, pero también hay datos generados automáticamente por dispositivos y sensores, como cámaras de seguridad, GPS y sistemas meteorológicos.
El procesamiento y análisis de estos datos masivos nos permite tomar decisiones más informadas y desarrollar soluciones innovadoras para mejorar nuestras vidas.
5.2. Visualización, transporte y almacenaje de los datos
5.2.1. Visualización de datos
La visualización de datos es una técnica que permite representar información de manera gráfica para facilitar su comprensión. Al trabajar con Big Data, es crucial convertir los datos en información comprensible y accesible. Gráficos, mapas, tablas y diagramas son ejemplos de herramientas de visualización que nos ayudan a entender patrones, tendencias y relaciones entre los datos.
5.2.2. Transporte de datos
El transporte de datos es el proceso de transferir datos de un lugar a otro, como entre servidores, dispositivos o sistemas. En el caso del Big Data, el transporte es un desafío, ya que implica mover grandes volúmenes de datos de forma rápida y segura. Las redes de alta velocidad, como las redes de fibra óptica, son esenciales para el transporte eficiente de datos masivos.
Ejemplo del mundo real – SPOTIFY
Un ejemplo de transporte de datos masivos que podríamos tener en cuenta es la forma en que la música se transmite a través de internet. Cuando alguien quiere escuchar una canción en una plataforma de streaming como Spotify, los datos de esa canción se envían desde los servidores de Spotify a través de internet hasta el dispositivo del usuario. El transporte de estos datos es importante porque si la conexión a internet es lenta o inestable, la canción puede detenerse o incluso no reproducirse en absoluto.
Piensa cómo se enviarían en tu misma aula un archivo entre dos portátiles conectados a internet. Podríamos enviar un archivo de música de un ordenador a otro a través de la red Wi-Fi del instituto y para ello, ambos equipos deben estar conectados de forma segura (con su correspondiente usuario y contraseña) a la WiFi del instituto, que tiene implementadas un buen número de medidas de seguridad que garantizan la integridad de los datos durante el transporte. Si no fuera así, cualquiera podría interceptar la comunicación, modificar los datos y corromper el archivo o incluso modificar su contenido, con lo que se generarían enormes problemas. Piensa ahora que en vez de estar enviando una simple canción entre dos amigos, lo que se están enviando son datos de transferencias bancarias entre millones de personas. ¿Ves ahora lo importante que es el transporte de datos masivos?
5.2.3. Almacenaje de datos
El almacenamiento de datos es otro aspecto importante en el manejo del Big Data. Debido al gran volumen de datos generados, es necesario contar con sistemas de almacenamiento que sean capaces de guardar y gestionar la información de manera eficiente.
Existen dos enfoques principales para almacenar datos:
- Almacenamiento local: Los datos se guardan en dispositivos físicos, como discos duros, servidores o sistemas de almacenamiento en red (NAS). Este enfoque puede ser costoso y limitado en cuanto a espacio y escalabilidad.
- Almacenamiento en la nube: Los datos se guardan en servidores remotos, accesibles a través de Internet. El almacenamiento en la nube ofrece escalabilidad y flexibilidad, ya que se puede ampliar o reducir según las necesidades. Sin embargo, la seguridad y privacidad de los datos deben ser consideradas al utilizar servicios en la nube.
En ambos casos, es crucial mantener copias de seguridad de los datos para prevenir pérdidas y garantizar la disponibilidad de la información.

En resumen, el manejo adecuado de la visualización, transporte y almacenamiento de datos es esencial para aprovechar al máximo el potencial del Big Data y extraer información valiosa de los datos masivos.
5.3. Recogida y análisis de datos
5.3.1. Recogida de datos
La recogida de datos es el proceso de recolectar información de diversas fuentes para su análisis y uso posterior. En el contexto del Big Data, es fundamental seleccionar y recopilar datos relevantes y de calidad para obtener resultados precisos y significativos. Existen diferentes métodos y herramientas para recolectar datos, como formularios en línea, sensores, registros de aplicaciones y dispositivos, entre otros.
Algunas consideraciones importantes en la recogida de datos son:
- Privacidad: Es fundamental respetar la privacidad de las personas y cumplir con las leyes y regulaciones de protección de datos. Esto incluye informar a los usuarios sobre la recopilación y uso de sus datos y solicitar su consentimiento cuando sea necesario.
- Calidad: Asegurar que los datos recogidos sean precisos y de calidad es crucial para obtener resultados confiables en el análisis.
Ejemplo del mundo real – INVESTIGACIÓN SOBRE USO DE DISPOSITIVOS MÓVILES
Imagina que estamos trabajando en una investigación sobre el uso de dispositivos móviles en jóvenes de 12 a 13 años. Para recopilar datos relevantes y de calidad, podríamos diseñar una encuesta online (con Google Docs, por ejemplo) que pregunte sobre el tipo de dispositivo que utilizan, la frecuencia de uso, las aplicaciones que más usan y el tiempo que dedican a ellas.
Sería importante asegurarnos de respetar la privacidad de los encuestados, por lo que incluiríamos una sección en la que les informamos sobre el uso que se dará a sus respuestas y pediríamos su consentimiento para participar. También deberíamos asegurarnos de que la encuesta sea fácil de entender y responder para los jóvenes, tal vez incluyendo preguntas con opciones de respuesta múltiple o de selección rápida.
Una vez que recolectemos los datos, podemos analizarlos para obtener información valiosa sobre el uso de dispositivos móviles en esta edad. Podríamos descubrir, por ejemplo, que la mayoría de los jóvenes usan su teléfono para jugar videojuegos o ver videos, y que esto ocupa una cantidad significativa de su tiempo libre. Este tipo de información podría ayudar a padres y educadores a tomar decisiones informadas sobre el uso de dispositivos móviles en esta edad.
5.3.2. Análisis de datos
El análisis de datos es el proceso de examinar, procesar y transformar los datos recogidos para extraer información útil y generar conocimientos. En el Big Data, el análisis se lleva a cabo mediante herramientas y técnicas avanzadas que pueden manejar grandes volúmenes de datos y encontrar patrones, tendencias y relaciones ocultas.
Hay diferentes tipos de análisis de datos en el contexto del Big Data:
- Análisis descriptivo: Se enfoca en describir y resumir los datos, utilizando herramientas de visualización y estadísticas para identificar patrones y tendencias.
- Análisis predictivo: Utiliza algoritmos y técnicas de aprendizaje automático para predecir eventos futuros o comportamientos basándose en los datos históricos.
- Análisis prescriptivo: Propone acciones o decisiones basadas en el análisis predictivo, optimizando resultados y solucionando problemas.
El análisis de datos es un componente clave en el proceso de toma de decisiones y en la generación de soluciones basadas en datos. Al dominar las habilidades de recogida y análisis de datos, seremos capaces de transformar grandes cantidades de información en conocimientos valiosos para mejorar nuestra vida diaria y resolver problemas complejos.
Ejemplo del mundo real – LA TIENDA DE GOLOSINAS
Supongamos que tenemos una tienda de golosinas y queremos aumentar nuestras ventas. Para lograrlo, podemos recopilar datos sobre nuestros clientes, como su edad, género, preferencias de sabor y frecuencia de visita.
Una vez que tenemos estos datos, podemos realizar diferentes tipos de análisis para obtener información valiosa.
Por ejemplo, con el análisis descriptivo, podemos obtener una imagen general de nuestros clientes y determinar cuáles son los productos más populares. Podríamos descubrir que los adolescentes prefieren los dulces ácidos y los adultos prefieren los chocolates.
Con el análisis predictivo, podemos usar modelos matemáticos para predecir qué productos podrían venderse mejor en el futuro. Podríamos descubrir que, en función de las tendencias de compra anteriores, el lanzamiento de una nueva línea de gomitas ácidas podría tener un gran éxito entre los adolescentes.
Finalmente, con el análisis prescriptivo, podemos usar los resultados del análisis predictivo para recomendar acciones específicas. En nuestro caso, podríamos recomendar que la tienda se concentre en promocionar la nueva línea de gomitas ácidas en las redes sociales y colocarlos en un lugar destacado en la tienda.
5.4. Generación de nuevos datos
5.4.1. Creación de datos a través de la interacción
Todos generamos datos de diferentes maneras a medida que interactuamos con el mundo digital. Los estudiantes, al igual que otros usuarios de Internet, contribuís a la creación de nuevos datos cada vez que utilizáis dispositivos electrónicos y aplicaciones. Algunos ejemplos de cómo generamos datos son:
- Redes sociales: Cuando publicamos, comentamos o compartimos contenido en plataformas como Facebook, Instagram o Twitter, creamos nuevos datos.
- Búsquedas online: Cada vez que realizamos una búsqueda en Google o en otro motor de búsqueda, se generan datos relacionados con nuestras consultas y preferencias.
- Aplicaciones móviles: Al utilizar aplicaciones en nuestros dispositivos, generamos datos sobre nuestras actividades, ubicación y preferencias.

5.4.2. Datos generados automáticamente
Además de los datos que creamos mediante nuestras interacciones, también se generan datos automáticamente a través de diferentes dispositivos y tecnologías. Estos datos pueden incluir información sobre el funcionamiento y uso de dispositivos, así como datos recopilados por sensores y sistemas integrados en nuestra vida cotidiana. Algunos ejemplos de datos generados automáticamente son:
- Dispositivos IoT (Internet de las Cosas): Los dispositivos conectados a la red, como termostatos inteligentes, cámaras de seguridad y electrodomésticos, generan datos sobre su funcionamiento y uso.
- Sensores: Los sensores en dispositivos como teléfonos móviles, relojes inteligentes y sistemas de transporte recopilan datos sobre factores como la ubicación, el movimiento y las condiciones ambientales.
- Sistemas de registro: Las aplicaciones y sistemas informáticos registran automáticamente información sobre su funcionamiento, eventos y errores, generando datos útiles para la monitorización y el mantenimiento.

5.4.3. Importancia de la generación de datos
La generación de nuevos datos es esencial para alimentar el crecimiento y desarrollo de la tecnología, así como para mejorar nuestra comprensión del mundo. Al analizar y utilizar estos datos, podemos tomar decisiones mejor informadas y desarrollar soluciones innovadoras en campos como la medicina, la educación, el transporte y la ciencia.
Es importante que entiendas que debes ser consciente de la información que generas y compartes, así como a proteger tu privacidad y seguridad online. Además, al comprender cómo se generan y utilizan los datos, puedes aprender a aprovechar el poder del Big Data para resolver problemas y mejorar tu vida.
5.5. Entrada y salida de datos de los dispositivos y las apps
5.5.1. Entrada de datos
La entrada de datos se refiere al proceso de introducir información en un dispositivo o aplicación para su procesamiento o almacenamiento. En el ámbito del Big Data, la entrada de datos puede realizarse de diversas maneras, como a través de teclados, pantallas táctiles, cámaras, micrófonos, sensores y conexiones a Internet. Algunos ejemplos de entrada de datos en el día a día de los estudiantes incluyen:
- Escribir mensajes en aplicaciones de chat o redes sociales.
- Tomar fotos o grabar videos con dispositivos móviles.
- Completar formularios online o participar en encuestas.
5.5.2. Salida de datos
La salida de datos es el proceso de extraer o mostrar información procesada o almacenada en un dispositivo o aplicación. Los datos de salida pueden presentarse en forma de texto, imágenes, audio, video u otros formatos, según el tipo de dispositivo o aplicación y el propósito de la información. Algunos ejemplos de salida de datos en la vida cotidiana de los alumnos incluyen:
- Ver resultados de búsqueda en un motor de búsqueda como Google o Bing.
- Escuchar música o ver videos en plataformas de streaming como Spotify o Twitch.
- Recibir notificaciones de aplicaciones móviles o mensajes en redes sociales como Whatsapp o TikTok.
5.5.3. La importancia de la entrada y salida de datos en el Big Data
La entrada y salida de datos son procesos fundamentales en la gestión del Big Data, ya que permiten la interacción entre usuarios, dispositivos y aplicaciones. A medida que se generan y consumen más datos, es importante que entiendas cómo se llevan a cabo estos procesos y cómo afectan tu vida diaria y la privacidad de tu información.
Además, al comprender cómo funcionan la entrada y salida de datos, puedes aprender a utilizar dispositivos y aplicaciones de manera más eficiente y segura, así como a desarrollar habilidades críticas en el manejo y análisis de información en la era digital.
5.6. Periodismo de datos
5.6.1. ¿Qué es el periodismo de datos?
El periodismo de datos es una rama del periodismo que utiliza técnicas de análisis y visualización de datos para contar historias y descubrir patrones ocultos en grandes volúmenes de información. Combina habilidades de periodismo, estadística y tecnología para comunicar información de manera efectiva y accesible a través de gráficos, mapas y otros elementos visuales.
5.6.2. Importancia del periodismo de datos
El periodismo de datos es especialmente importante en la era del Big Data, ya que ayuda a los periodistas y al público en general a comprender y dar sentido a la gran cantidad de información disponible online. Algunas ventajas del periodismo de datos son:
- Mejor comprensión de temas complejos: Al visualizar datos y analizar patrones, el periodismo de datos puede ayudar a simplificar y aclarar temas complicados para que sean más fáciles de entender.
- Verificación y precisión: El periodismo de datos permite verificar y contrastar información de múltiples fuentes, lo que puede mejorar la precisión y la confiabilidad de las noticias.
- Participación del público: Al presentar información de forma atractiva y fácil de entender, el periodismo de datos puede aumentar la participación y el interés del público en temas importantes.
5.6.3. Ejemplos de periodismo de datos
El periodismo de datos se puede aplicar a una amplia variedad de temas y formatos. Algunos ejemplos incluyen:
- Mapas interactivos que muestran información geográfica, como la distribución de la población, la incidencia de enfermedades o la evolución de las elecciones políticas.
- Gráficos de barras o líneas que comparan datos a lo largo del tiempo, como el crecimiento económico, las tendencias en la educación o las emisiones de gases de efecto invernadero.
- Visualizaciones que revelan relaciones y conexiones entre datos, como las redes sociales, las conexiones entre empresas y políticos, o las relaciones entre productos y sus fabricantes.
En resumen, el periodismo de datos es una herramienta valiosa para ayudarte como estudiante y al público en general a comprender y dar sentido al mundo en el que vivimos. A través del análisis y la visualización de datos, el periodismo de datos permite contar historias y descubrir patrones ocultos en la información, lo que puede mejorar nuestra comprensión de temas importantes y facilitar la toma de decisiones informadas.
5.7. Data scraping
5.7.1. ¿Qué es el data scraping?
El data scraping, también conocido como web scraping, es una técnica para extraer información de sitios web y almacenarla en un formato estructurado, como una hoja de cálculo o una base de datos. Esta técnica utiliza programas y scripts para navegar automáticamente por páginas web, identificar datos relevantes y copiarlos en un formato legible por máquinas.
5.7.2. Usos del data scraping
El data scraping se utiliza en una variedad de aplicaciones y campos, incluidos:
- Investigación de mercado: Las empresas pueden utilizar el data scraping para recopilar información sobre precios, productos y opiniones de los consumidores en diferentes sitios web y plataformas.
- Análisis de redes sociales: El data scraping puede ayudar a analizar las tendencias y el comportamiento de los usuarios en plataformas como Facebook, Twitter e Instagram.
- Monitoreo de noticias: Los periodistas y analistas pueden utilizar el data scraping para seguir las noticias y las discusiones en línea sobre temas específicos o eventos.
- Agregadores de contenido: Los sitios web y aplicaciones que recopilan información de diversas fuentes y la presentan en un formato unificado a menudo utilizan data scraping para obtener datos de sitios web de terceros.
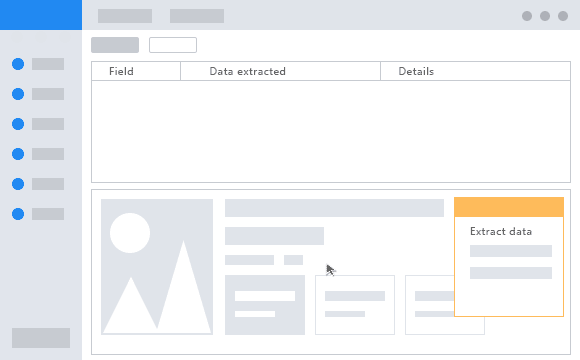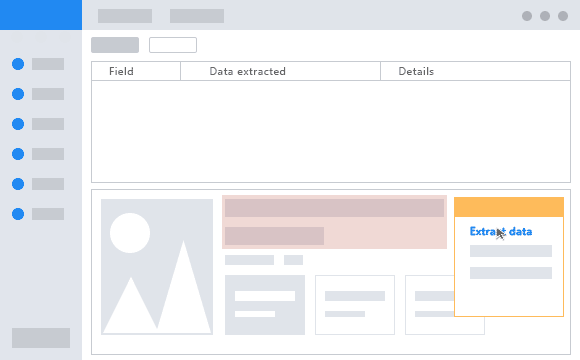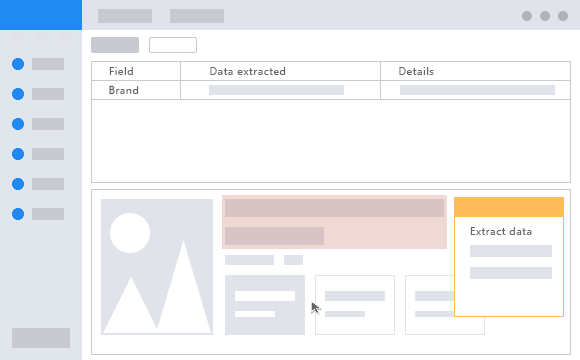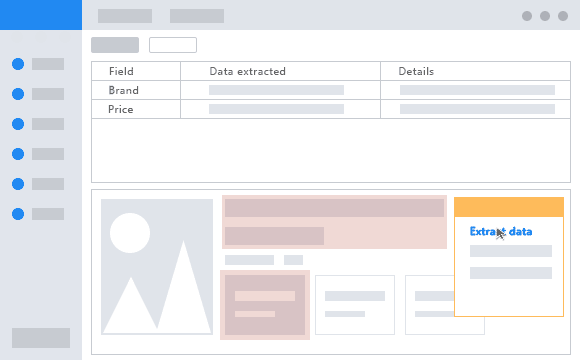
Ejemplo del mundo real – EL COMPARADOR DE PRECIOS
Un ejemplo de uso del data scraping en la vida real podría ser el seguimiento de precios en una tienda online. Cuando un usuario busca un producto en una tienda online, el precio puede variar con el tiempo debido a promociones, descuentos, o cambios en el stock. Utilizando técnicas de data scraping, es posible recolectar la información de precios de manera automatizada para compararlos con otros sitios web y así obtener una mejor oferta. Esto es útil para los consumidores que quieren obtener el mejor precio posible en sus compras online, ya que se aseguran que el producto que están comprando está al precio más bajo posible en este momento. [Sin embargo, es importante mencionar que algunos sitios web pueden prohibir el uso de técnicas de scraping y es importante respetar las normas de uso de cada sitio web].
5.7.3. Consideraciones éticas y legales
Aunque el data scraping puede ser una herramienta útil para recopilar información de sitios web, también plantea preocupaciones éticas y legales. Algunas consideraciones importantes incluyen:
- Privacidad: El data scraping puede invadir la privacidad de las personas si se utiliza para recopilar información personal sin su consentimiento.
- Propiedad intelectual: Copiar y almacenar contenido de sitios web puede violar las leyes de propiedad intelectual y derechos de autor.
- Términos de servicio: Muchos sitios web tienen términos de servicio que prohíben el uso de data scraping, y su incumplimiento puede resultar en sanciones legales.
Es importante que aprendas a utilizar el data scraping de manera ética y legal, respetando la privacidad de los demás y las leyes y regulaciones aplicables. Además, al comprender cómo funciona el data scraping, puedes aprender a proteger tu propia información online y a reconocer las implicaciones de compartir datos en sitios web y aplicaciones.
Beatriz Perez
Buenos días,
Información muy interesante para abordar inicialmente Big Data.
Si bien, alguna recomendación práctica para realizar un proyecto y/o propuesta de trabajo en aula para el alumnado de 2º Bachillerato?
Muchas gracias de antemano