Currículo: esta unidad desarrolla todos los saberes básicos del Bloque G – Datos masivos correspondiente a 1ºESO. Además, se evalúan los criterios que puedes encontrar al final de esta página.
Tabla de contenidos
- 7.1. Introducción al Big Data
- 7.2. Visualización, transporte y almacenaje de datos generados
- 7.3. Entrada y salida de datos
- 7.4. Introducción a los metadatos
- 7.5. Recursos adicionales
Vivimos en un mundo donde la cantidad de información generada por segundo es inabarcable. Desde sensores en dispositivos IoT hasta interacciones en redes sociales y compras online, cada acción deja una huella digital que, si se analiza correctamente, puede desvelar patrones y tendencias que de otro modo pasarían desapercibidos. Esta capacidad para decodificar la complejidad de nuestro mundo es lo que hace del Big Data una herramienta indispensable para mejorar nuestra calidad de vida.
En este tema comenzaremos a entender algunos de los mecanismos que lo hacen posible.
7.1. Introducción al Big Data
El Big Data es un concepto fundamental en la actualidad. Se refiere a la gestión y análisis de grandes volúmenes de datos que superan las capacidades de las herramientas tradicionales de procesamiento.
Para que entiendas de qué estamos hablando, veamos un ejemplo de helados, ahora que empieza el buen tiempo.
Supongamos que quisieras saber cuáles son los sabores de helado más populares entre los clientes de tu heladería preferida. Así podrías hacerlo:

Te sientas frente a la tienda y anotas cada vez que alguien compra un helado y qué sabor elige. Registras esa información en una hoja de papel o en un ordenador. Miras tus datos y haces preguntas como: «¿Cuál es el sabor más común?» o «¿Cuántas personas prefieren el chocolate?» Puedes crear gráficos o tablas para mostrar esta información. Utilizas tus datos para predecir cosas. Por ejemplo, podrías decir: «Basado en las tendencias, creo que el próximo verano el helado de fresa será muy popular». Con toda esta información, puedes decidir qué sabores de helado ofrecer más o cuándo hacer promociones especiales.
El análisis de datos es como resolver acertijos con números y hechos, un poco como ser un detective de la información.
Si ahora, en vez de capturar, registrar y analizar los datos de una heladería, lo intentas hacer de todas las heladerías de Europa en tiempo real, estaríamos hablando de Big Data, pero el proceso, aunque automatizado, sería el mismo.

A continuación, veremos algunos aspectos clave de esta forma de trabajar.
Como ya sabes, el Big Data surge debido al crecimiento exponencial de la cantidad de datos generados por sistemas informáticos, sensores, redes sociales y otras fuentes.
La necesidad de extraer información valiosa de esos datos llevó al desarrollo de técnicas y herramientas específicas.
El Big Data, por tanto, no se trata solo de la cantidad de datos –volumen-, sino también de su variedad -los datos provienen de diversas fuentes y formatos (texto, imágenes, vídeos,…)-, velocidad -los datos se generan y actualizan rápidamente- y veracidad -la confianza y la precisión de los mismos-.
Más allá de las magnitudes, consideramos el Big Data como un cambio de forma de trabajo en la toma de decisiones. Implica la capacidad de procesar y analizar datos masivos para obtener conocimientos significativos.
Existen, además, estándares y prácticas recomendadas para el manejo eficiente de datos masivos, que abordan aspectos como la seguridad, la privacidad y la interoperabilidad.
7.2. Visualización, transporte y almacenaje de datos generados
Para que los datos estén disponibles y podamos trabajar con ellos, primero debemos completar una serie de tareas muy importantes que nos garanticen que los datos no han sufrido alteraciones. Por eso, estos tres aspectos del trabajo con datos masivos también desempeñan un papel protagonista.
Cuando hablamos de visualización de datos nos referimos a representar los datos de manera gráfica o visual para que podamos identificar patrones, tendencias y relaciones. Esto ayuda mucho a comprender la información contenida en grandes conjuntos de datos.
Algunas técnicas comunes de visualización incluyen gráficos, diagramas, mapas de calor y tablas.
Además de eso, el transporte de datos, nos permite poder moverlos de un lugar a otro. Esto puede implicar transferir datos desde sensores, dispositivos o sistemas de almacenamiento a centros de procesamiento o bases de datos. Las redes de comunicación, como Internet, juegan un papel fundamental en el transporte eficiente de datos.
Si esto no fuera así, tareas tan comunes que haces a diario, como poder escuchar una canción en Spotify o ver un directo de Twitch, no serían posibles.
Por último, el almacenaje de datos, hace referencia a dónde y cómo se guardan los datos. En el mundo del Big Data, necesitamos sistemas de almacenamiento escalables y eficientes.
Algunas opciones comunes incluyen bases de datos relacionales, sistemas de archivos distribuidos y almacenamiento en la nube. La elección del método de almacenamiento depende de factores como la cantidad de datos, la velocidad de acceso y los requisitos de seguridad.

7.3. Entrada y salida de datos
Cuando trabajamos en el sector del Big Data es fundamental entender que el modelo de trabajo es del tipo «entrada-proceso-salida», que además, es común a todos los sistemas informáticos.
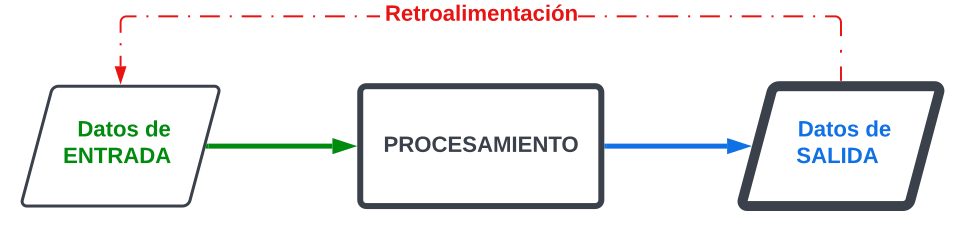
La entrada de datos es el primer paso del modelo. Aquí, los datos se introducen en dispositivos de procesamiento, como ordenadores, a través de dispositivos de entrada adecuados -llamados periféricos de entrada-, como teclados, escáneres, lectores de códigos de barra, cámaras de vídeo, micrófonos, etc.
Además, a esos periféricos la entrada puede venirles de distintas fuentes, como sensores, bases de datos, archivos, redes sociales o cualquier otra fuente de datos.
Por ejemplo, sensores de temperatura registrando datos ambientales o una aplicación web recopilando comentarios de usuarios.

El procesamiento de los datos, por su parte, es la etapa intermedia. Los datos se procesan de acuerdo con reglas predefinidas. Este procesamiento puede implicar análisis, transformación, agregación o cualquier otro cálculo necesario para extraer información significativa.
Por ejemplo, aplicar algoritmos de aprendizaje automático para predecir tendencias o filtrar datos irrelevantes.

La salida de datos es el último paso. Aquí, los datos procesados se muestran o envían a los usuarios finales a través de distintos dispositivos -los periféricos de salida-, como pantallas, impresoras, altavoces, proyectores, archivos, etc.
Esta salida puede ser en forma de informes, gráficos, visualizaciones, alertas, notificaciones o incluso otras acciones automatizadas.
Por ejemplo, un panel de control que muestra estadísticas de ventas, o un sistema de recomendación que sugiere productos a los usuarios, o un sistema que envía notificaciones de alertas.

7.4. Introducción a los metadatos
Los metadatos son información adicional que describe a otros datos. Son fundamentales para comprender y gestionar los conjuntos de datos masivos, porque proporcionan contexto y detalles sobre los datos principales.
Por ejemplo, en una fotografía digital, los metadatos pueden incluir la fecha de captura, la ubicación, la cámara utilizada y la configuración de la exposición de la lente.
Sitios web como EXIF.tools o Jimpl, te permiten subir una imagen y conocer, entre otras cosas su fecha de captura, lugar de realización, características de la cámara, etc.
Existen varios tipos de metadatos, de los cuales podemos destacar:
- Metadatos descriptivos: describen el contenido de los datos. Pueden incluir títulos, descripciones, palabras clave y categorías.
- Metadatos administrativos: se utilizan para gestionar los datos. Incluyen información sobre derechos de autor, permisos de acceso y fechas de creación y modificación.
- Metadatos técnicos: están relacionados con las características técnicas de los datos. Por ejemplo, el formato del archivo, la resolución de una imagen o la frecuencia de muestreo de un archivo de audio.
Los metadatos permiten la búsqueda, organización y recuperación eficiente de datos. Sin ellos, sería difícil encontrar y comprender grandes volúmenes de información. Son de gran ayuda para los científicos de datos y analistas para interpretar los resultados y aplicar los algoritmos adecuados.
Veamos algunos ejemplos de su uso en nuestro día a día:
- Búsqueda en la web: los motores de búsqueda utilizan metadatos para indexar y clasificar páginas web por orden de relevancia que les permite mostrarte la página que contiene la información que necesitas cuando buscas algo concreto en cuestión de segundos.
- Gestión de bibliotecas masivas: ayudan a organizar y etiquetar libros, imágenes o vídeos para que cuando intentes localizar un recurso gráfico, puedas obtenerlo al instante.
- Análisis de datos científicos: los metadatos en experimentos científicos proporcionan detalles sobre las condiciones, instrumentos y variables utilizadas. De esta manera, otros investigadores pueden replicar experimentos, complementarlos o mejorarlos. Así conseguimos enormes avances que mejoran nuestra calidad de vida.
7.5. Recursos adicionales
Esta presentación te facilitará extraer lo más importante del tema:
José Manuel N. M.
Hola. Creo que los apartados deberían empezar por 7. Un saludo y enhorabuena por tu web.
Lope
Hola José Manuel,
llevas toda la razón, te agradezco el aviso, ya lo he corregido.
Gracias por tu comentario,
saludos.