Currículo: esta unidad desarrolla todos los saberes básicos del Bloque G – Datos masivos correspondiente a 1ºESO. Además, se evalúan los criterios que puedes encontrar al final de esta página.
Tabla de contenidos
- 7.1. Aplicaciones del Big Data en la sociedad actual
- 7.2. Datos cualitativos y cuantitativos
- 7.3. Distinción entre datos y metadatos
- 7.4. Ciclo de vida de los metadatos
En este tema vamos a descubrir cómo la manipulación de grandes volúmenes de datos tiene la capacidad de transformar nuestra vida: desde nuestras preferencias de compra hasta los tratamientos médicos que recibimos.
Cada acción que realizamos, cada interacción que tenemos, genera datos. Saber interpretar estos datos es clave para mejorar tanto nuestra vida personal como el rendimiento empresarial. Por ello, este tema tiene como objetivo entrenar nuestra capacidad de análisis crítico sobre el impacto del uso de los datos en la actualidad.
Para recordar de qué trata el Big Data, te recomiendo que repases los apuntes del año pasado, puesto que ahora vamos a ampliar lo que ya conocemos.
7.1. Aplicaciones del Big Data en la sociedad actual
Como sabemos, a través de la recopilación, procesamiento y análisis de grandes volúmenes de datos, se pueden obtener un conocimiento muy valioso que nos permita tomar decisiones informadas. Pero, todavía no hemos estudiado en qué áreas concretas de nuestra vida diaria se aplican los datos masivos. A continuación, veremos algunos de los sectores más importantes en los que se trabajan actualmente este tipo de tecnologías:
7.1.1. Marketing
Las empresas utilizan datos para comprender mejor a sus clientes y personalizar sus estrategias de marketing. Este análisis de datos permite segmentar a los consumidores según sus preferencias y comportamientos de compra.
Además, las campañas publicitarias se optimizan utilizando datos sobre la respuesta del público -cuál es la mejor hora para mostrar un anuncio, en qué dispositivos, en qué formatos, etc.-, así pueden medir la efectividad de los anuncios.
Por ejemplo, una tienda online de moda desea segmentar a sus clientes para personalizar sus estrategias de marketing. Utilizan datos recopilados de compras anteriores, interacciones en el sitio web y preferencias de productos. En un tipo de segmentación -llamada por Beneficios-, identifican a los clientes que buscan ciertos productos por los beneficios específicos que brindan: compras de vestidos de fiesta para ocasiones especiales, ropa cómoda para el uso diario, o prendas de alta calidad y diseño exclusivo. Otro tipo de segmentación se centra en la Ocasión: observan cómo reaccionan los clientes ante productos lanzados para ocasiones específicas, como colecciones de Navidad o verano. De esta manera, si un cliente compra regularmente bañadores en primavera, la tienda puede ofrecerle promociones específicas durante esa temporada, antes que al resto de usuarios, porque es altamente probable que se cierre una venta.

7.1.2. Salud
El Big Data se utiliza para predecir brotes de enfermedades, qué tratamientos se ajustan mejor a qué tipo de pacientes y, en general, en mejorar la atención médica. Los registros electrónicos de salud y los datos del genoma se analizan para identificar patrones. De la misma manera, la investigación médica se beneficia del análisis de grandes conjuntos de datos, para crear fármacos o protocolos de atención que mejoran nuestra calidad de vida.
Por ejemplo, tras el estudio pormenorizado de miles de pacientes de diabetes, el análisis de los datos permitió detectar ciertos hábitos de vida que, en la actualidad, se trabajan para prevenir la aparición de la enfermedad. Y funciona con mucho éxito.
7.1.3. Deporte
Hace ya algunos años que los equipos que participan en distintas competiciones utilizan datos para analizar el rendimiento de los jugadores y prevenir lesiones. Los atletas monitorean su salud durante el entrenamiento usando dispositivos portátiles conectados a sensores. El análisis posterior de los datos ayuda a diseñar estrategias ganadoras y optimizar el rendimiento en competiciones.
Por ejemplo, los jugadores de fútbol entrenan desde 2010 con chalecos GPS para estudiar sus movimientos, su implicación y rendimiento en ciertas zonas del campo. En la actualidad han evolucionado y permiten registrar numerosos datos sobre su rendimiento físico. De esta manera, el equipo técnico del club es capaz de preparar sus enfrentamientos seleccionando mucho mejor a los jugadores que pueden dar un mejor rendimiento, en función de la estrategia deportiva que se necesite aplicar en cada partido.

7.1.4. Logística
Las empresas de transporte utilizan datos para optimizar rutas y horarios. El seguimiento en tiempo real de vehículos y paquetes mejora la eficiencia de la logística garantizando tiempos de entrega cada vez más cortos.
Por ejemplo, una empresa de transporte de mercancías por carretera utiliza datos en tiempo real sobre el estado del tráfico, las condiciones climáticas y las restricciones de horarios, de cada uno de los camiones que tiene en ruta en cada momento. Como resultado, los productos llegan más rápido a los clientes, se optimizan los recursos y se incrementan los beneficios. Ventajas para todos.

7.1.5. Ciudades Inteligentes
Los datos recopilados por sensores conectados a una amplia variedad de dispositivos, se utilizan para mejorar la calidad de vida en las ciudades. El tráfico, la seguridad, la gestión de residuos y la eficiencia energética se benefician del análisis de esos datos captados por los sensores.
Por ejemplo, en Barcelona, se han instalado contenedores equipados con sensores que miden su nivel de llenado. Esto ha permitido optimizar las rutas de los camiones de la basura, reduciendo el consumo de combustible y mejorando los niveles de contaminación de la ciudad.

7.1.6. Industria
A través de la recopilación y análisis de datos masivos, las industrias pueden prever fallos en la maquinaria, mejorar la cadena de producción y personalizar productos a las necesidades de los consumidores. Esto lo hacen de diversas maneras, como por ejemplo:
- Las fábricas utilizan sensores en las líneas de ensamblaje para recoger datos en tiempo real sobre el rendimiento de las máquinas y la eficiencia de los procesos de producción. Este análisis permite ajustar las operaciones para maximizar la velocidad y minimizar los residuos.
- Mediante la recopilación de datos de sensores en maquinaria pesada y sistemas de producción, se pueden predecir fallos antes de que ocurran. Esto no solo evita tiempos de inactividad costosos sino que también prolonga la vida útil del equipo.
Ejemplo factoría de coches
Una fábrica de coches puede utilizar datos recopilados de sus robots de ensamblaje para prever cuándo una máquina está probablemente a punto de fallar. A través del análisis de patrones en los datos de rendimiento, como vibraciones inusuales o aumentos de temperatura, pueden programar mantenimientos durante periodos de baja producción, asegurando que el proceso de fabricación no se interrumpa y manteniendo la eficacia de la línea de producción.
Ejemplo grandes eléctricas
Las grandes empresas de producción eléctrica están utilizando Big Data para monitorizar y gestionar el consumo de energía de manera más eficiente. Los datos recogidos de los sistemas de energía pueden analizarse para identificar tendencias de uso y desarrollar estrategias para reducir el consumo: picos de demanda según el día, las condiciones climáticas o grandes eventos sociales programados. Esto permite ajustar los precios a la demanda de cada hora, por eso luego sabemos cuál es la mejor hora para poner la lavadora o qué día es el más barato para cocinar con el horno.
Aunque a primera vista no te lo parezca, el Big Data tiene un impacto muy significativo en nuestra sociedad, hasta el punto que muchas de las comodidades que hoy disfrutas son consecuencia de la aplicación directa del análisis de datos masivos.
7.2. Datos cualitativos y cuantitativos
Para entender un poco mejor cómo funciona la recogida, análisis y uso de los datos masivos, es necesario saber diferenciar entre los dos tipos fundamentales de datos que se utilizan en el campo del Big Bata: los datos cualitativos y los datos cuantitativos.
Los datos cualitativos son aquellos que describen cualidades que no se pueden medir con números. Estos datos suelen ser descriptivos y se recogen a través de observaciones, entrevistas o encuestas abiertas.
Por ejemplo, opiniones sobre un nuevo producto, descripciones de experiencias en un evento o respuestas a preguntas abiertas en una encuesta sobre hábitos de lectura.

Por su parte, los datos cuantitativos son aquellos que se pueden medir y expresar numéricamente. Esto facilita su análisis estadístico y su comparación objetiva.
Por ejemplo, cantidad de libros leídos por un estudiante en un año, número de asistentes a un evento deportivo, o resultados de exámenes expresados en calificaciones numéricas.
De esta forma, los datos cualitativos pueden proporcionar contexto a los patrones que aparecen en los datos cuantitativos.
Por ejemplo, si un estudio muestra que las ventas de un producto están disminuyendo -datos cuantitativos-, los datos cualitativos de las encuestas de clientes pueden ofrecer razones detrás de esta tendencia.
En muchos proyectos de Big Data, se combinan ambos tipos de datos para obtener una visión más completa de un problema.
7.3. Distinción entre datos y metadatos
La distinción que hicimos en el apartado anterior formaba parte del mundo de los datos, pero cuando trabajamos con Big Data, es fundamental distinguir si la magnitud que estamos observando es un dato o un metadato.
El curso pasado ya vimos una introducción a los metadatos, que te invito a repasar. De forma resumida, los metadatos son datos sobre otros datos. Proporcionan información adicional que ayuda a entender, usar o gestionar datos primarios -los que vimos en el apartado anterior-.
Por ejemplo, la nota de un alumno en un examen sería un dato, pero la fecha del examen, el número de preguntas y su duración, son metadatos, porque aportan un contexto que nos permite entender mejor al dato. De igual manera, una imagen es un dato, pero quién la hizo y dónde, son metadatos.
Los metadatos son muy importantes para el control de calidad de los datos, ya que proporcionan información sobre la fuente, la integridad y la relevancia de los datos, lo que es vital para evaluar su fiabilidad.
Saber distinguir si estamos ante un dato o un metadato permite elaborar procesos de gestión de datos más efectivos, especialmente en términos de seguridad y cumplimiento de normativas, ya que los metadatos pueden indicar quién tiene acceso a los datos, cuándo y cómo se pueden compartir o utilizar.
Cuando observamos una magnitud, ¿cómo podemos distinguir si estamos ante un dato o un metadato?
Lo que hacemos es evaluar la información para entender su naturaleza y también su propósito. Por ejemplo, si la información que estamos viendo es el resultado de una medición, es muy probable que sea un dato. Pero si la información sirve para describir o contextualizar otros datos, es probable que sea un metadato.
Una última cuestión muy importante que debes tener en cuenta es que una información puede considerarse un dato en un contexto determinado, pero también un metadato en otro contexto concreto.
Por ejemplo, si estamos almacenando diversos tipos de contenido multimedia, los datos serían los audios, las imágenes, los vídeos, las animaciones, etc. En el caso del vídeo sus metadatos podrían ser su duración, su número de reproducciones o la fecha en la que se publicó. Sin embargo, si estamos en el contexto del análisis de estadísticas de varios vídeos, esas mismas magnitudes -duración, número de reproducciones o fecha- serían datos.
7.4. Ciclo de vida de los metadatos
El ciclo de vida de los metadatos describe las etapas por las que pasa esta información desde su creación hasta su eliminación, asegurando que los datos que describen sean utilizados y mantenidos adecuadamente.
Estas son las etapas que forman parte del ciclo de vida de los metadatos:
- Creación: esta es la etapa inicial donde los metadatos son generados. Puede ser un proceso automático o manual. Los metadatos se crean para describir aspectos clave de los datos, como el autor, la fecha de creación, la ubicación y el formato de los datos.
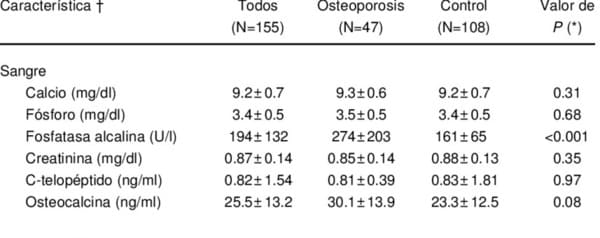
Por ejemplo, cuando haces una foto con tu teléfono, se generan automáticamente metadatos que incluyen la fecha y hora de captura, la ubicación GPS y detalles técnicos como la apertura y la velocidad del obturador de la lente.
- Almacenamiento: una vez creados, los metadatos deben ser almacenados de manera que puedan ser fácilmente accesibles y asociados con los datos que describen. Esto implica guardarlos en un formato y ubicación que permita su rápida recuperación y que esté protegido contra accesos no autorizados o corrupción.
Por ejemplo, etiquetas como «factura», «contrato» o «informe» facilitan la búsqueda y clasificación de los documentos de una empresa.

- Gestión: durante esta etapa, los metadatos pueden sufrir modificaciones. Esto incluye la actualización de la información para reflejar cualquier cambio en los datos asociados. La gestión también implica asegurar que los metadatos sigan siendo relevantes y útiles para los usuarios y los sistemas que dependen de ellos.
Por ejemplo, la fecha y la hora de la última reproducción de un vídeo.
- Uso: durante esta fase, los usuarios acceden a ellos. Así ayudan a los usuarios a comprender el contexto y la relevancia de los datos.
Por ejemplo, cuando accedes a un vídeo puedes ver su resolución, su duración y sus hashtags, de manera que puedes filtrarlos por cada uno de ellos para localizar el vídeo que te interesa.
- Archivado: cuando los datos alcanzan su final en términos de utilidad operativa, tanto los datos como sus metadatos asociados pueden ser archivados. Esto significa que no estarán disponibles para los usuarios, pero sí para las personas que los administran. El archivado de los metadatos debe garantizar que se puedan recuperar junto con los datos si es necesario en el futuro.
Por ejemplo, cuando finaliza un curso los profesores podemos archivar el classroom de una asignatura -les desaparece a los alumnos, pero se queda guardado para el profesor-, para consultarlo el año siguiente y comprobar cómo fue el rendimiento de un alumno que ahora está intentando recuperar la asignatura.
- Eliminación: finalmente, cuando los datos y sus metadatos ya no son necesarios o útiles, deben ser eliminados de manera segura para proteger la privacidad y evitar la acumulación innecesaria de información obsoleta. La eliminación debe hacerse de acuerdo con las políticas de retención de datos y cumplimiento legal.
Por ejemplo, cuando lo resultados de análisis de sangre de un hospital dejan de tener validez -porque hace demasiado tiempo que se hicieron y ya no son representativos de la salud actual del paciente-, es obligatorio destruirlos con una trituradora de papel y almacenarlos en unos contenedores especiales que son recogidos por empresas especializadas que tienen autorización para destruirlos. Tirar simplemente a la papelera un documento así, es un delito.

Cada una de estas etapas requiere medidas específicas para garantizar que los metadatos se mantienen útiles y seguros a lo largo de su vida útil. La correcta gestión del ciclo de vida de los metadatos es fundamental para maximizar su utilidad y facilitar la eficiencia de los sistemas que dependen de grandes volúmenes de datos.
Para afianzar un poco más la comprensión de este concepto, veamos el ciclo de vida completo del metadato «número de reproducciones» de una canción en Spotify:
| Fase | Metadato «número de reproducciones» |
|---|---|
| Creación | Se inicializa a cero cuando la canción es añadida al sistema por primera vez. |
| Almacenamiento | Se actualiza y almacena en la base de datos cada vez que la canción es reproducida. |
| Gestión | Cuando un usuario reproduce la canción, puede ver las reproducciones que lleva y se suma 1 cada vez que un usuario la escucha. |
| Uso | Los usuarios o sistemas de recomendación consultan este metadato para determinar la popularidad de la canción o para hacer recomendaciones personalizadas. |
| Archivado | Spotify deja de ofrecer la canción a los usuarios, pero sigue guardada en su base de datos, para referencias futuras y estadísticas históricas. |
| Eliminación | Si la canción es eliminada del sistema, el metadato también se borra, perdiendo así el registro de su uso. |