Currículo: esta unidad cubre parte de los saberes básicos del Bloque A – Programación (PRYC.2.A.3) correspondiente a 2º Bachillerato. Además, se evalúan los criterios que puedes encontrar al final de esta página.
Tabla de contenidos
- 1. Ciclo de vida del software
- 2. Metodologías de desarrollo de software
- 3. Enfoque top-down
- 4. Diagramas de flujo, pseudocódigo y código
- 5. Entornos de desarrollo integrado
- 6. Depuración
- 7. Control de versiones
- 8. Trabajo en equipo
En nuestra vida diaria dependemos constantemente de programas informáticos: desde la alarma de tu móvil que se activa cada mañana, hasta las aplicaciones que utilizamos para comunicarnos, estudiar, escuchar música o reservar un billete de tren. Sin embargo, pocas veces nos paramos a pensar cómo se crean esas aplicaciones, qué pasos sigue un equipo de programadores desde que surge una idea hasta que finalmente aparece en una tienda de aplicaciones lista para descargar.
El propósito de este primer tema es que entendamos que la programación no consiste simplemente en «escribir código». Antes de llegar a esa fase, es necesario planificar, organizar y diseñar de forma cuidadosa lo que queremos construir, igual que un arquitecto no comienza a levantar un edificio sin planos previos.

Aquí aprenderemos qué diferentes metodologías de desarrollo existen y por qué unas son más adecuadas que otras en función del tipo de proyecto, lo que va a condicionar todo el resto del proceso de ingeniería.
Este tema es el punto de partida para todo lo que haremos en el curso. Si conseguimos comprender cómo se organiza el proceso de creación de software, estaremos preparados para dar el siguiente paso: aprender a programar con sentido, evitando errores y trabajando como auténticos profesionales.
1. Ciclo de vida del software
Cuando pensamos en una aplicación que usamos todos los días —por ejemplo WhatsApp, TikTok o la app del banco donde miramos nuestro saldo— es probable que pensemos que alguien simplemente se sentó delante del ordenador, escribió código durante unos días y el programa ya estaba listo.

Pero en realidad no funciona así, ni de lejos. Crear software es un proceso mucho más organizado y planificado, que se estructura en lo que llamamos ciclo de vida del software.
Podemos compararlo con lo que sucede cuando construimos una casa. Antes de poner un ladrillo, un arquitecto hace planos, se estudian las necesidades de los futuros habitantes, se diseñan los espacios, se construye con los materiales adecuados y finalmente se revisa que todo funcione (electricidad, fontanería, etc.). Solo cuando todo está probado, se certifica su funcionamiento y la casa puede ser habitada.
Con el software ocurre exactamente lo mismo: hay fases claras que guían desde la idea inicial hasta la aplicación terminada que los usuarios descargan en sus dispositivos.
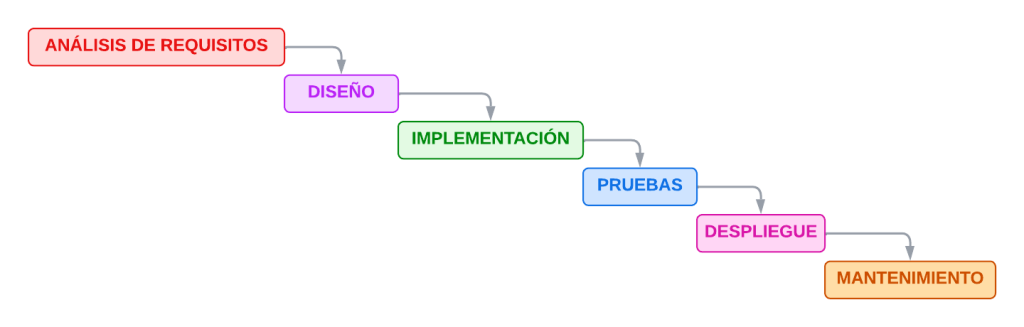
En general, el ciclo de vida del software se divide en varias etapas:
- Análisis de requisitos: aquí se estudia qué necesita realmente el usuario. Imagina que en tu instituto quisieran una aplicación para reservar ordenadores en la biblioteca. No se empieza programando directamente; primero se pregunta: ¿quién la usará?, ¿qué funciones son necesarias?, ¿debe enviar notificaciones?

- Diseño: una vez entendidas las necesidades, se decide cómo se va a construir el sistema. Esto incluye diagramas de bases de datos, estructuras de pantallas, organización de menús… En el ejemplo anterior, se definiría cómo se guardan las reservas, cómo accede cada alumno y cómo se evita que dos personas reserven el mismo ordenador.
- Programación (o implementación): ahora sí, se escribe el código que hace que la aplicación cobre vida.
- Pruebas: antes de «entregar» el software, se comprueba que funciona bien. Aquí se detectan errores, como que la app permita reservar un ordenador a una hora ya ocupada.
- Despliegue: se publica la aplicación, empieza su vida real. Los usuarios la usan y reportan fallos, o bien piden nuevas funciones. En ese momento comienza el mantenimiento, que es la parte más larga del ciclo de vida del software.
Si lo piensas bien, este proceso también ocurre en tu día a día. Cuando preparas un trabajo en grupo para una asignatura, seguís pasos similares: primero decidís qué hay que hacer (análisis), después repartís tareas y hacéis un esquema (diseño), elaboráis el trabajo (programación), lo revisáis juntos (pruebas) y finalmente lo entregáis. Y lo mejoráis si el profesor os da feedback (mantenimiento).
Todas las empresas de desarrollo de software, startups tecnológicas o incluso los equipos informáticos de bancos, hospitales o administraciones públicas trabajan siguiendo un ciclo similar a este. No hacerlo supondría crear programas llenos de errores, poco útiles y muy costosos de mantener.
Tarea 1.1 – Análisis de requisitos
Si preguntáramos a 10 jefes de proyecto, 8 te dirían que la fase más importante, con mucha diferencia es la primera, la captación y análisis de requisitos, puesto que si no entendemos qué quiere el cliente nunca podremos entregar un proyecto que satisfaga sus necesidades.
Por ello, vamos a practicar esta fase.
Ve al classroom de la asignatura y realiza la Tarea 1.1.
2. Metodologías de desarrollo de software
Ya sabemos que el ciclo de vida del software está formado por varias fases (análisis, diseño, programación, pruebas y despliegue). Pero ¿cómo se organizan esas fases? ¿Siempre se hacen en el mismo orden?
A lo largo de la historia de la informática se han creado distintas metodologías de desarrollo, que son simplemente formas de organizar el trabajo en un proyecto de software.
Igual que si tuvieras que preparar una obra de teatro en clase, podéis hacerlo de dos formas muy distintas:
- Una opción sería ensayar todas las escenas en orden, una tras otra, sin volver atrás. Si algo falla, es complicado de cambiar.
- Otra opción sería ensayar en grupos de escenas, revisarlas poco a poco y corregir sobre la marcha, hasta que toda la obra queda lista.
Eso mismo ocurre en el software. Las metodologías marcan si trabajamos de manera más rígida o más flexible.
De forma muy resumida, podemos destacar tres grandes enfoques:
- Modelo en cascada: se trabaja en fases que van una detrás de otra, como si fueran escalones. Primero se analiza, después se diseña, luego se programa, luego se prueba. Es sencillo de entender, pero muy rígido: si un cliente pide un cambio al final, resulta muy caro de incluir.
- Modelo en espiral: en lugar de hacer todo de una vez, se trabaja en «vueltas» o ciclos. En cada vuelta se analizan los riesgos, se diseñan partes, se prueban y se avanza un poco más. Se parece a construir una maqueta inicial y mejorarla en cada vuelta.

- Metodologías ágiles: son las más utilizadas en la actualidad, sobre todo en startups y empresas de software. Aquí se trabaja en equipos pequeños, dividiendo el proyecto en tareas cortas llamadas «sprints». Cada dos o tres semanas se entrega una versión que ya funciona, aunque sea muy básica, y se mejora poco a poco escuchando al cliente. Ejemplos de estas metodologías son Scrum o Kanban, muy usadas en empresas de desarrollo web y de apps móviles.
Las metodologías, por tanto, no son otra cosa que distintas formas de organizar el mismo trabajo.
3. Enfoque top-down
Cuando te enfrentas a un problema complejo —por ejemplo, organizar una excursión de fin de curso— si intentas hacerlo todo de golpe, te abruma. Hay demasiadas cosas que decidir: el lugar, el transporte, el alojamiento, el dinero, la comida, las actividades, las autorizaciones,… Lo más lógico es dividir el problema en partes más pequeñas y hacer que distintas personas se encarguen de resolver cada una de ellas.
En programación pasa exactamente lo mismo. Si un desarrollador tiene que crear una aplicación completa, no puede resolverlo de una sola vez. La estrategia que utilizamos se llama enfoque top-down (de arriba hacia abajo). Consiste en partir de la idea general y descomponerla poco a poco en tareas más simples, hasta que cada una pueda traducirse fácilmente a código.
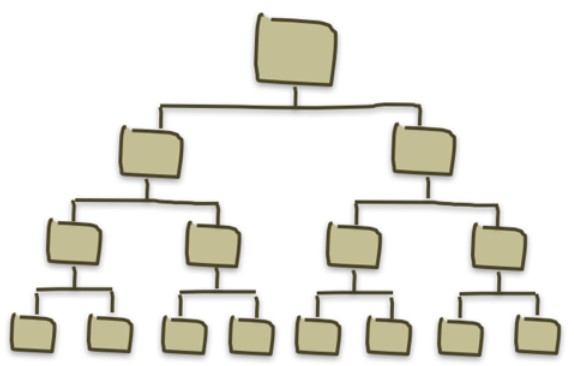
Veámoslo con un ejemplo cotidiano. Supongamos que queremos programar un pequeño juego de preguntas y respuestas. Si lo pensamos globalmente, parece complicado. Pero con el enfoque top-down podemos dividirlo así:
- Mostrar una pregunta al usuario.
- Recibir su respuesta.
- Comprobar si es correcta.
- Sumar puntos si acierta.
- Mostrar la puntuación final.
Cada uno de esos pasos, a su vez, puede dividirse a su vez en subproblemas más pequeños. Por ejemplo, mostrar una pregunta puede implicar:
- elegir una pregunta al azar,
- mostrarla por pantalla,
- y guardar cuál es la respuesta correcta.
De esta forma, un proyecto que parecía enorme se convierte en una colección de pequeños objetivos alcanzables. Esa es la esencia de la fragmentación de problemas: dividir para conquistar.
En la práctica profesional, esta técnica es la base del trabajo en equipo. Adoptar el enfoque top-down nos enseña a pensar como programadores, a no rendirnos ante problemas grandes, y a entender que todo sistema informático —por complejo que parezca— está formado por pequeñas piezas que encajan unas con otras de forma lógica.
Tarea 1.2 – Fragmentación de problemas
Saber fragmentar un problema correctamente asignando tareas al equipo es una habilidad que se cotiza muy alta en el mundo de la programación, por eso vamos a entrenarla.
Ve al classroom de la asignatura y realiza la Tarea 1.2.
4. Diagramas de flujo, pseudocódigo y código
Acabamos de aprender a dividir un problema complejo en partes más pequeñas, hasta que cada una pueda resolverse por separado. Sin embargo, aún no hemos hablado de cómo expresar esas soluciones de una forma clara, ordenada y comprensible para cualquier persona, incluso antes de escribir una sola línea de código. Esa es precisamente la función de las herramientas que veremos a continuación.
4.1. Diagramas de flujo: pensar de forma visual
Los diagramas de flujo son representaciones gráficas de los algoritmos. Sirven para visualizar la secuencia de pasos que sigue un programa y las decisiones que puede tomar.
Cada figura geométrica tiene un significado específico:
- El óvalo indica el inicio o el fin del proceso.
- El paralelogramo representa la entrada o salida de datos.
- El rectángulo muestra una acción o instrucción (por ejemplo, una operación matemática).
- El rombo señala una decisión, es decir, una comparación o una condición que puede dar lugar a dos caminos distintos.
Veámoslo con un ejemplo muy sencillo: un algoritmo que decide si un alumno aprueba o suspende en función de su nota.

Los diagramas de flujo son ideales para los primeros pasos del razonamiento algorítmico, porque convierten lo abstracto en algo visible. De hecho, muchas empresas todavía los utilizan en la fase de diseño para explicar cómo funcionará un sistema antes de programarlo.
4.2. Pseudocódigo: del pensamiento visual al pensamiento textual
Una vez que comprendemos cómo fluye la lógica del programa en el diagrama, el siguiente paso es expresarla por escrito. El pseudocódigo es una forma de describir un algoritmo usando palabras que se parecen a las de un lenguaje de programación, pero sin necesidad de conocer su sintaxis exacta.
Su nombre lo explica: «pseudo» significa “falso” o “aparente”. No es un lenguaje real, pero se parece lo suficiente como para que más adelante podamos traducirlo fácilmente a uno verdadero.
Por ejemplo, el pseudocódigo del mismo ejercicio anterior podría escribirse así:
INICIO
LEER nota
SI nota >= 5 ENTONCES
MOSTRAR "Aprobado"
SINO
MOSTRAR "Suspenso"
FIN SI
FINFíjate en que usamos verbos naturales (leer, mostrar), pero mantenemos una estructura ordenada y lógica. Lo importante no es la forma exacta, sino que quien lea el pseudocódigo entienda fácilmente lo que hace el programa.
El pseudocódigo se usa mucho en la fase de análisis y diseño, cuando el equipo necesita definir el comportamiento del software sin preocuparse todavía de los errores de sintaxis o de las particularidades de cada lenguaje. En la práctica profesional, los analistas de sistemas o los jefes de proyecto utilizan pseudocódigo para comunicar ideas con los programadores.
4.3. Del pseudocódigo al código real
Una vez que el algoritmo está claro y probado mentalmente, el siguiente paso es traducirlo a un lenguaje de programación real, que pueda ser entendido por el ordenador.
En nuestro ejemplo, el pseudocódigo anterior en Java se convertiría en:
import java.util.Scanner;
public class EvaluacionAlumno {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("Introduce la nota: ");
double nota = sc.nextDouble();
if (nota >= 5) {
System.out.println("Aprobado");
} else {
System.out.println("Suspenso");
}
sc.close();
}
}Como puedes ver, la estructura lógica es idéntica. Solo cambian las palabras clave y la sintaxis que exige el lenguaje. Por eso, podemos decir que programar no es otra cosa que darle a un ordenador las instrucciones precisas de un algoritmo que ya hemos diseñado antes.
5. Entornos de desarrollo integrado
Hasta ahora hemos aprendido a pensar como programadores: a dividir problemas, a expresar algoritmos mediante diagramas de flujo o pseudocódigo y a traducirlos después a un lenguaje real como Java. Pero para poder escribir, probar y corregir programas de forma eficiente, necesitamos un lugar donde hacerlo. Ese lugar se llama entorno de desarrollo integrado, más conocido por sus siglas: IDE (del inglés Integrated Development Environment).
Un IDE es, en esencia, el taller del programador. Igual que un mecánico necesita herramientas, un programador necesita un entorno que le facilite el trabajo. Dentro de un IDE podemos encontrar las siguientes herramientas:
- Editor de código: es donde escribimos las instrucciones del programa. Suele incluir funciones útiles como el coloreado de palabras clave, el autocompletado y la indentación automática, que ayudan a que el código sea más legible.
- Compilador o intérprete integrado: traduce el código que escribimos al lenguaje que entiende el ordenador.
- Depurador (debugger): permite ejecutar el programa paso a paso, ver el valor de las variables y detectar errores sin necesidad de hacerlo «a ciegas».
- Gestor de archivos: mantiene organizados todos los ficheros relacionados con un mismo programa.
- Consola de salida: muestra los resultados, mensajes o errores que genera el programa al ejecutarse.
Podemos imaginarlo como una especie de «cuaderno inteligente» para programar: no solo escribimos en él, sino que además nos corrige, nos sugiere mejoras y nos ayuda a entender en qué nos hemos equivocado.

En el aula solemos usar IDE sencillos y visuales, especialmente si el alumnado se inicia en la programación:
- Thonny o Mu Editor, para programar en Python de forma intuitiva, sin complicaciones.
- Arduino IDE, en proyectos de robótica o electrónica, que permite cargar código directamente en una placa Arduino.
- MakeCode, para micro:bit, que incluso ofrece programación por bloques y un simulador integrado.
A medida que el nivel de programación aumenta, se utilizan entornos más potentes:
- PyCharm o Visual Studio Code, muy usados por profesionales que trabajan con Python, JavaScript o C++.
- Eclipse o IntelliJ IDEA, habituales en empresas que desarrollan en Java.
En el mundo profesional, el uso de un IDE mejora la productividad, reduce los tiempos de desarrollo y mejora la calidad del software.
6. Depuración
Cuando escribimos un programa por primera vez, lo habitual es que no funcione a la primera. Aparecen errores, el resultado no es el esperado o el programa directamente se bloquea. Esto no significa que lo hayamos hecho mal: forma parte natural del proceso de desarrollo. En realidad, programar es tanto escribir código como corregirlo, y es precisamente aquí donde entra en juego la depuración.
La depuración (en inglés debugging, literalmente «quitar bichos») consiste en detectar, analizar y corregir los errores de un programa hasta que funcione correctamente.
Para comprender bien qué es depurar, primero debemos distinguir los tipos de errores que pueden aparecer en un programa.
- Errores de sintaxis: son los más básicos y fáciles de detectar. Se producen cuando escribimos algo que el lenguaje no entiende, como olvidarnos un punto y coma en Java o escribir mal una palabra clave. El propio IDE suele avisarnos con un subrayado rojo o un mensaje de error.

- Errores de ejecución: aparecen cuando el programa se ejecuta, pero ocurre algo inesperado, como intentar dividir entre cero o acceder a una posición inexistente de una lista.

- Errores lógicos: son los más difíciles de detectar, porque el programa funciona, pero hace algo diferente de lo que debería. En este caso, la sintaxis es correcta, pero el razonamiento no.

Estos errores son inevitables, incluso para programadores con años de experiencia. Lo importante no es evitarlos, sino saber localizarlos y resolverlos de manera metódica.
Existen muchas estrategias que podemos aplicar para depurar un programa, pero todas dependen de las herramientas disponibles en nuestro entorno de programación. Las iremos viendo conforme vayamos adquiriendo soltura programando.
7. Control de versiones
Cuando trabajamos en un proyecto, es muy normal que tengamos que hacer cambios constantemente. A veces añadimos una nueva función, otras corregimos errores o simplemente probamos una idea diferente. El problema aparece cuando, después de varios intentos, ya no sabemos cuál era la versión que funcionaba bien, o queremos recuperar algo que borramos hace unos días.
Para evitar esto existe una técnica llamada control de versiones, que consiste en guardar el historial de todos los cambios que se realizan sobre un proyecto a lo largo del tiempo. Dicho de otra forma: el control de versiones es un sistema que permite viajar atrás y adelante en la evolución del código, igual que una máquina del tiempo, para saber qué cambió, cuándo y por qué.
Podemos entenderlo mejor con un ejemplo cotidiano. Imagina que estás preparando tu trabajo final de curso en un documento de texto. Cada pocos días haces cambios y guardas nuevos archivos con nombres como:
→ Trabajo_final_v1.docx
→ Trabajo_final_v2_bueno.docx
→ Trabajo_final_definitivo_de_verdad.docx
→ Trabajo_final_DEFINITIVO_ahora_sí.docx
Seguro que te suena. A medida que vas guardando versiones, pierdes el control sobre cuál es la buena y qué diferencias hay entre ellas. El control de versiones hace eso de forma automática y ordenada. Cada vez que guardas, el sistema no crea un archivo nuevo, sino que registra los cambios concretos respecto a la versión anterior (qué líneas se han modificado, añadido o borrado) y los almacena junto con la fecha y el autor del cambio.
Así, si más tarde algo falla, puedes volver exactamente a la versión en la que todo funcionaba sin perder el trabajo hecho después.

En las empresas de software, los equipos trabajan en proyectos que pueden durar meses o incluso años. Sería imposible gestionar miles de líneas de código sin un sistema que registre los cambios. Por eso, todas las organizaciones utilizan algún tipo de control de versiones, ya sea a través de herramientas digitales (como Git o Subversion) o integradas en plataformas de trabajo en equipo.
En la actualidad la herramienta que utiliza la práctica totalidad de la industria del desarrollo de software es GitHub.

8. Trabajo en equipo
El control de versiones no solo sirve para mantener un historial de cambios, sino también para que varias personas puedan trabajar sobre un mismo proyecto sin molestarse unas a otras. Y es que, aunque solemos imaginar al programador como alguien que trabaja solo frente al ordenador, en la realidad profesional el software siempre se desarrolla en equipo.
Cada aplicación que usamos —desde un videojuego hasta una red social— es el resultado del trabajo coordinado de muchas personas: programadores, diseñadores, analistas, testers, jefes de proyecto, redactores de documentación, y un largo etcétera.
Los equipos suelen dividirse en roles y tareas específicas. Por ejemplo:
- Un grupo diseña la interfaz que verá el usuario.
- Otro programa la lógica que hay detrás (qué ocurre cuando pulsamos un botón).
- Otro se encarga de la base de datos o de la conexión con internet.
Cada parte forma un engranaje dentro de una máquina mayor, y todas deben encajar perfectamente. Esto exige comunicación constante, responsabilidad y coordinación.

Para que un grupo funcione bien, cada integrante necesita saber qué tarea tiene asignada, cuándo debe terminarla y cómo encaja dentro del conjunto. Por eso se suelen usar métodos y herramientas que facilitan la organización.
- Reuniones de planificación: al inicio del proyecto se definen los objetivos y se reparten las tareas.
- Listas de tareas o tableros visuales: ayudan a seguir el progreso del grupo.
- Revisión entre compañeros: antes de dar por terminada una parte, otro miembro del grupo revisa el trabajo para detectar errores o proponer mejoras.
- Comunicación clara: comentar los problemas, pedir ayuda y compartir avances evita malentendidos y mejora el resultado final.
En las empresas tecnológicas actuales, los equipos de desarrollo utilizan herramientas colaborativas para organizar proyectos, compartir código y comunicarse. Plataformas como Slack, Notion, Trello o Discord se combinan con los sistemas de control de versiones para que todos puedan trabajar en paralelo sin perder coherencia.

El resultado es un modelo de trabajo muy parecido al de cualquier otro ámbito profesional: personas con distintas habilidades que colaboran hacia un objetivo común.
El éxito no depende de que cada uno sea un genio aislado, sino de que el grupo funcione como un equipo coordinado, capaz de planificar, comunicar, respetar plazos y resolver conflictos de forma constructiva.