Currículo: esta unidad cubre parte de los saberes básicos del Bloque B – Datos e Información (PRYC.2.B.1) correspondiente a 2º Bachillerato. Además, se evalúan los criterios que puedes encontrar al final de esta página.
Tabla de contenidos
- 1. Qué es una base de datos
- 2. Bases de datos relacionales
- 3. Sistemas Gestores de Bases de Datos (DBMS)
- 4. Diseño de bases de datos relacionales
- 5. Normalización de bases de datos
- 6. Introducción al lenguaje SQL
- 7. Creación de bases de datos y tablas con SQL
Cada vez que usamos el móvil, entramos en Classroom, jugamos a Poki o compramos en TikTok, estamos generando información. Nosotros vemos pantallas, botones o listas, pero el sistema lo que realmente gestiona son datos estructurados.
Conviene distinguir dos ideas clave.
Por un lado, el dato, que es un valor aislado (un nombre, una nota, una fecha). Por otro, la información, que surge cuando esos datos se organizan y adquieren sentido. Cuando vemos nuestras calificaciones en iPasen o en Moodle, no estamos viendo datos sueltos, sino información procesada a partir de muchos datos relacionados entre sí.
Aquí es donde empezamos a intuir que no basta con guardar cosas, sino que hay que organizarlas correctamente para poder usarlas después de forma eficaz.
Hasta ahora, cuando hemos querido guardar información en un ordenador, lo hemos hecho usando archivos: documentos de texto, hojas de cálculo, archivos con código fuente, etc. Este sistema funciona bien cuando la cantidad de datos es pequeña y el uso es muy simple, pero empieza a fallar en cuanto el volumen crece o varias personas acceden a la información al mismo tiempo.
1. Qué es una base de datos
Con todo lo anterior, ya podemos definir qué es una base de datos. Una base de datos es un conjunto de datos organizados de forma estructurada, almacenados de manera que puedan consultarse, modificarse y gestionarse de forma eficiente.
Si lo pensamos con una analogía sencilla, una base de datos no es un “cajón donde meter cosas”, sino un archivo inteligente, capaz de responder preguntas como:
- ¿Qué alumnos tienen más de una asignatura suspensa?
- ¿Qué productos se han vendido este mes?
- ¿Qué jugadores están conectados ahora mismo?
2. Bases de datos relacionales
Una vez que hemos entendido por qué son necesarias las bases de datos, ahora debemos centrarnos en qué tipo de bases de datos vamos a estudiar y cómo organizan la información internamente. Todo lo que veremos a partir de ahora se apoyará en este modelo –Modelo Relacional-, mayoritario en la industria del software, así que es fundamental entender bien los conceptos.
2.1. Concepto de base de datos relacional
Cuando hablamos de bases de datos relacionales, nos referimos a un tipo concreto de base de datos que organiza la información en tablas relacionadas entre sí. Cada tabla almacena datos de un mismo tipo, y las relaciones permiten conectar esa información sin duplicarla innecesariamente.
La idea fundamental es que los datos no están aislados. Una base de datos relacional permite expresar relaciones del mundo real: un alumno pertenece a un grupo, un pedido corresponde a un cliente, una nota está asociada a una asignatura. Estas relaciones son las que dan sentido a la información.

2.2. Las tablas como estructura básica de almacenamiento
En una base de datos relacional, la tabla es la estructura fundamental. Podemos entender una tabla como una cuadrícula organizada en filas y columnas, muy similar a una hoja de cálculo, aunque con normas mucho más estrictas.
Cada tabla representa un conjunto de elementos del mismo tipo. Por ejemplo, una tabla de alumnos, una tabla de asignaturas o una tabla de profesores. Esta separación es intencionada: evita mezclar información distinta y facilita su mantenimiento.
Tabla: CLIENTES
| ID_CLIENTE | NOMBRE | DIRECCIÓN | TELÉFONO |
| 23 | Jorge | C/Nueva, 21 | +34615883677 |
| 34 | Álvaro | C/Alta, 32 | +34711454778 |
| 35 | Xabi | C/Soria, 54 | +11234321190 |
| 38 | Andrés | Avda. América, 12 | +14345321100 |
Es importante interiorizar que una base de datos no suele tener una única tabla, sino varias tablas especializadas, cada una con una función clara dentro del sistema.
2.3. Campos, registros y valores
Dentro de una tabla distinguimos tres elementos principales:
- Campos (atributos, columnas): definen qué información se almacena, como: nombre, edad o curso.

- Registros (tuplas, filas): representan cada registro individual, por ejemplo: cada alumno concreto.

- Valores: son los datos reales que ocupan cada celda de la tabla. Además, los valores SIEMPRE serán de un tipo de dato definido sobre cada campo. Estos tipos de datos incluyen:
- Texto: para almacenar cadenas de caracteres, como nombres, direcciones o descripciones.
- Números: existen varios tipos numéricos, incluidos enteros y decimales, para almacenar números con o sin decimales.
- Fecha y hora: para almacenar fechas, horas o ambas, permitiendo realizar operaciones como cálculos de intervalos o comparaciones de fechas.
- Booleano: para almacenar valores verdadero o falso, útil para definir campos con solo dos posibles valores, estados o condiciones.
- Blob (Binary Large Object): para almacenar datos binarios, como imágenes, archivos de audio o cualquier otro tipo de archivo multimedia.
Cada columna tiene un significado fijo y un tipo de dato concreto, mientras que cada fila contiene los valores correspondientes a un elemento real. Esta estructura rígida es precisamente lo que permite que las bases de datos sean eficientes.
2.4. Claves primarias
Para que una tabla funcione correctamente, necesitamos una forma de identificar de manera única cada fila. Para eso utilizamos la clave primaria.
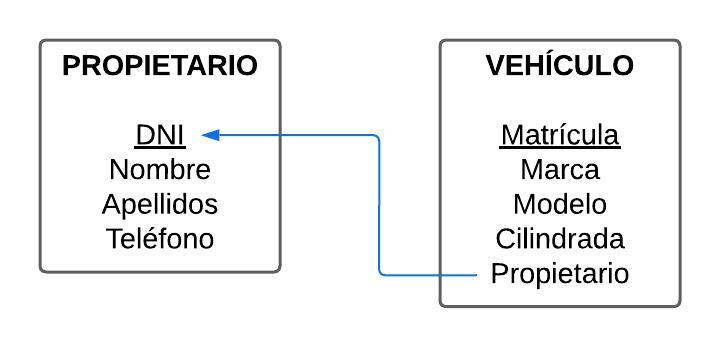
La clave primaria es una columna (o conjunto de columnas) cuyo valor no se repite nunca y permite distinguir cada registro del resto. En una tabla de personas, por ejemplo, ¿qué dato distingue a cada persona de manera universal? El DNI, pues ese campo es la clave primaria (PK).
Es obligatorio definir una clave primaria para cada tabla de una base de datos.
La clave primaria cumple una triple función fundamental:
- Identificación: permite referirnos a un registro concreto sin ambigüedad.
- Organización: facilita el acceso rápido a la información.
- Relación: permite que otras tablas hagan referencia a ese registro.
Sin claves primarias, las relaciones entre tablas serían una inagotable fuente de errores.
Además, la clave primaria la identificamos visualmente porque es el único campo que aparecerá subrayado.
PROPIETARIO
| DNI | Nombre | Apellidos | Teléfono |
| 45112558B | Juan | Méndez Álvarez | 665000111 |
| 27000112Z | Alberto | García Castaño | 778552121 |
| 41445698K | Lucia | López Toledo | 615804142 |
2.5. Relaciones entre tablas
Una de las preguntas más habituales al empezar es por qué no guardar toda la información en una única tabla. La respuesta es sencilla: hacerlo así genera repetición de datos, errores y dificultades de mantenimiento.
Las bases de datos relacionales apuestan por dividir la información en varias tablas y relacionarlas entre sí. Por ejemplo, en lugar de repetir el nombre de una asignatura en cada alumno, creamos una tabla de asignaturas y otra de alumnos, y las conectamos mediante una relación.

Estas relaciones se establecen utilizando claves primarias y claves ajenas (secundarias o foráneas -FK-), que son columnas que apuntan a registros de otra tabla. Gracias a este mecanismo, conseguimos bases de datos más limpias, coherentes y fáciles de ampliar.
Ejercicio 4.1 – Identificando entidades
Ahora que ya tienes conocimientos básicos sobre lo más elemental de las bases de datos, debes entrenar la extracción de información de tu interés para construir una base de datos, a partir del enunciado de un problema.
Para cada uno de estos supuestos, se pide que:
- Identifiques cada una de las tablas que podría tener una base de datos que gestionara ese sistema de información, y les pongas un nombre representativo.
- Identifiques cada uno de los campos de cada tabla y elijas el tipo de dato más apropiado para ellos. Si en el enunciado no aparece de forma explícita un campo que crees que es necesario, puedes añadirlo por tu cuenta.
- Indica qué campo(s) has elegido como clave primaria, y si fuera necesario su(s) clave(s) ajena(s).
- Crea la tabla con sus correspondientes campos y rellénala con al menos 5 registros cada una.
Estos son los 5 supuestos sobre los que tienes que hacer todo lo anterior:
- COOL SHOES. Se desea desarrollar un sistema de información para gestionar las ventas, el inventario y los clientes de una zapatería online. Este sistema deberá permitir el registro de los productos disponibles, incluyendo información sobre el modelo, la talla, el color, el precio y la cantidad en stock. Además, deberá gestionar los pedidos realizados por los clientes, incluyendo datos del cliente, detalles del pedido y estado del envío.
- CITIUS ALTIUS FORTIUS. Un club deportivo necesita un sistema para administrar sus socios, las actividades deportivas que ofrece y las inscripciones a estas actividades. El sistema debe incluir información sobre cada socio (nombre, edad, contacto), las diferentes actividades disponibles (nombre de la actividad, horario, entrenador asignado) y el registro de inscripciones, indicando qué socio se ha inscrito en qué actividad.
- BEYOND LANGUAGE. Para una academia de inglés se requiere un sistema que gestione tanto a los estudiantes como a los cursos y profesores. Este sistema debe permitir registrar información sobre los estudiantes (nombre, nivel de inglés, contacto), los cursos ofrecidos (nombre del curso, nivel, horario, profesor) y las asignaciones de estudiantes a cursos, incluyendo las calificaciones obtenidas.
- GAS LOVERS. Un concesionario de motos necesita un sistema para administrar las ventas, el inventario de motos y los clientes. El sistema deberá incluir información detallada de cada moto (marca, modelo, año, precio, características técnicas), los datos de los clientes (nombre, dirección, contacto) y los registros de ventas realizadas, especificando la moto vendida, el cliente y la fecha de la venta.
- FOOD ROCKET. Un restaurante quiere implementar un sistema para gestionar su menú, las reservas y los pedidos a domicilio. Este sistema debe contener información sobre los platos del menú (nombre del plato, ingredientes, precio), las reservas realizadas por los clientes (nombre del cliente, número de comensales, fecha y hora de la reserva) y los pedidos a domicilio (detalles del pedido, dirección de entrega, estado del pedido).
Entrega: debes entregar un enlace público de Google Docs antes de la fecha límite indicada en classroom.
3. Sistemas Gestores de Bases de Datos (DBMS)
Ya sabemos cómo se organiza una base de datos relacional a nivel conceptual, pero ahora debemos entender con qué software vamos a crearlas, gestionarlas y consultarlas.
3.1. Qué es un Sistema Gestor de Bases de Datos
Un sistema gestor de bases de datos, es un programa que se encarga de almacenar, organizar y administrar las bases de datos. Nosotros no accedemos directamente a los archivos donde están guardados los datos, sino que interactuamos siempre a través del gestor.
Nuestro trabajo consistirá en enviarle instrucciones para que cree tablas, guarde información o nos devuelva resultados, y será el gestor quien se encargue de hacerlo correctamente.
Esta separación entre los datos y el acceso a ellos es muy importante para garantizar seguridad, coherencia y fiabilidad.
3.2. MySQL como sistema gestor de bases de datos relacional
MySQL es un SGBD relacional, lo que significa que trabaja con bases de datos formadas por tablas relacionadas entre sí. Utiliza el lenguaje SQL como medio de comunicación, que será el lenguaje que aprenderemos a usar en los siguientes apartados.

MySQL se emplea en multitud de contextos reales: páginas web, plataformas educativas, aplicaciones móviles o sistemas de gestión empresarial. Por tanto, aunque aquí lo usemos con fines didácticos, estamos aprendiendo a manejar una herramienta profesional.
Además, MySQL se caracteriza por ser robusto, eficiente y relativamente sencillo de usar, lo que lo convierte en una opción ideal para iniciarnos en el mundo de las bases de datos.
3.3. phpMyAdmin como herramienta de administración
Aunque MySQL es el sistema que gestiona realmente la base de datos, necesitamos una forma cómoda de interactuar con él. Aquí es donde entra phpMyAdmin, una herramienta web que nos permite administrar MySQL de forma visual y sencilla.

phpMyAdmin actúa como intermediario entre nosotros y MySQL. A través de su interfaz podemos crear bases de datos, definir tablas, insertar datos y ejecutar consultas SQL sin necesidad de usar el terminal de comandos. Esto facilita mucho el aprendizaje inicial y nos permite centrarnos en entender los conceptos.
3.4. Entorno de trabajo con MySQL y phpMyAdmin
Nuestro entorno de trabajo habitual será phpMyAdmin conectado a un servidor MySQL. Desde ahí escribiremos sentencias SQL y observaremos directamente sus efectos sobre la base de datos.
El proceso de trabajo será siempre el mismo: planteamos una necesidad, escribimos la instrucción SQL correspondiente, MySQL la ejecuta y phpMyAdmin nos muestra el resultado.
Para tener un entorno de trabajo que nos permita instalar un servidor de bases de datos y también la herramienta con la que gestionarlo, vamos a instalar el programa XAMPP que lo trae todo integrado.
⚠️ Lo que viene a continuación, es aplicable solo para usuarios Windows.
En la instalación, asegúrate de seleccionar sólo las opciones que necesitamos:

El resto de opciones de configuración puedes dejarlas tal y como vienen por defecto. Si en algún momento el ordenador te pide permiso para acceder a ubicaciones, conectar a Internet o cualquier otra opción, dale permiso para hacerlo.
Una vez que termine aparecerá esta ventanita, donde debes pulsar Start en Apache y en MySQL (flecha roja):
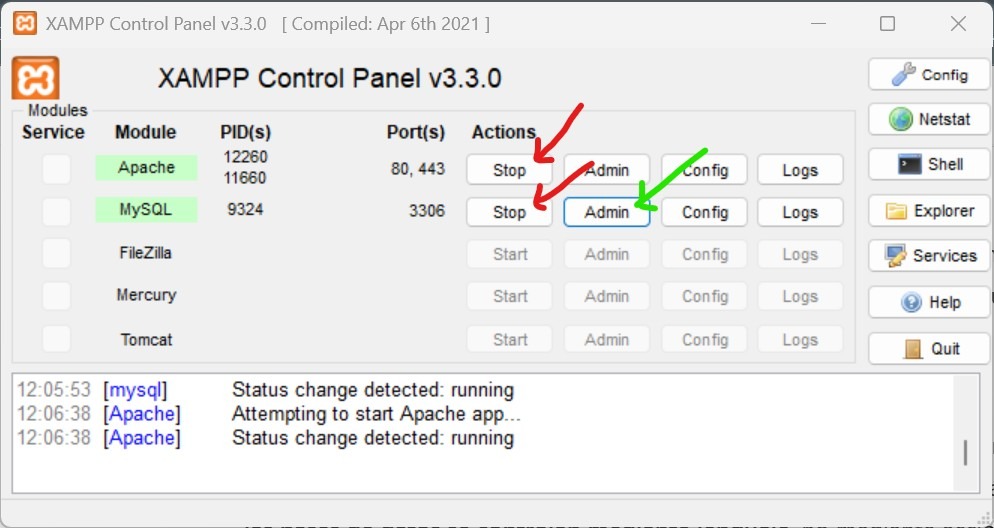
Una vez que tanto el servidor web como el de bases de datos estén iniciados (aparecerán sombreados de verde), ya podemos acceder a la herramienta phpMyAdmin para trabajar con nuestra base de datos. Para ello pulsa sobre el botón Admin (señalado por la flecha verde) y se abrirá la interfaz web de nuestra herramienta (http://localhost/phpmyadmin).
Todo listo para trabajar con nuestro Sistema Gestor de Bases de Datos.
Cuando termines una sesión de trabajo con XAMPP, siempre es buena idea parar los servidores pulsando en el botón Stop.
4. Diseño de bases de datos relacionales
Antes de escribir una sola línea de SQL o de crear tablas en MySQL, debemos aprender a pensar y diseñar correctamente una base de datos. Un buen diseño evita errores, repeticiones innecesarias y problemas futuros. Nuestro trabajo aquí no es técnico todavía, sino conceptual y lógico.
4.1. La importancia del diseño previo
Cuando se empieza a trabajar con bases de datos, es habitual querer crear directamente las tablas y empezar a insertar datos. Sin embargo, este enfoque suele provocar errores difíciles de corregir más adelante. Por eso, debemos asumir un concepto de enorme importancia: una base de datos bien diseñada empieza siempre antes de usar el ordenador.
Diseñar una base de datos consiste en 1️⃣ analizar la realidad que queremos representar, decidir 2️⃣ qué información es relevante y 3️⃣ cómo se relaciona entre sí. Si este paso se hace mal, aunque el SQL esté bien escrito, el sistema funcionará mal.
Un diseño correcto nos permite que la base de datos sea clara, ampliable y coherente, incluso cuando crece con el tiempo.
4.2. Entidades y atributos
El primer paso del diseño es identificar las entidades. Una entidad representa un elemento del mundo real sobre el que queremos almacenar información. Por ejemplo, un alumno, una asignatura o un profesor.
Cada entidad tiene una serie de atributos, que son las características que describen a esa entidad. En el caso de un alumno, algunos atributos podrían ser el nombre, la fecha de nacimiento o el curso.
Este paso requiere reflexión, porque no toda la información es igual de importante ni debe almacenarse de la misma forma.
4.3. Relaciones entre entidades
En la realidad, las entidades no existen de forma aislada. Un alumno está matriculado en asignaturas, un profesor imparte varias materias, una nota corresponde a un alumno y a una asignatura concreta. Estas conexiones se llaman relaciones.
Una relación indica cómo se vinculan dos entidades y cuántos elementos pueden intervenir. Por ejemplo, un alumno puede cursar varias asignaturas, y una asignatura puede tener muchos alumnos. Estas relaciones nos ayudan a entender cómo se organizarán después las tablas.
Aquí empezamos a ver claramente por qué las bases de datos relacionales no concentran toda la información en una sola tabla, sino que distribuyen los datos y los conectan de forma lógica.
4.4. Diagramas entidad–relación
Para representar visualmente todo lo anterior utilizamos los diagramas entidad–relación. Estos diagramas nos permiten ver de un vistazo las entidades, sus atributos y las relaciones entre ellas.
En un diagrama entidad–relación aparecen claramente:
- Las entidades, normalmente representadas mediante rectángulos.
- Los atributos, asociados a cada entidad.
- Las relaciones, se muestran como líneas que conectan unas entidades con otras.

Estos diagramas no dependen de MySQL ni de ningún lenguaje concreto. Son una herramienta de análisis que nos ayuda a pensar la base de datos antes de construirla, reduciendo errores y facilitando el paso a la fase técnica.
4.5. Del diagrama entidad–relación al esquema relacional
Una vez que tenemos claro el diagrama entidad–relación, debemos transformarlo en algo que MySQL pueda entender. Este paso se llama paso al esquema relacional.
El esquema relacional consiste en convertir cada entidad en una tabla, cada atributo en una columna y cada relación en una conexión entre tablas mediante claves. Aquí es donde aparecen de forma clara las claves primarias y las claves ajenas, que permitirán enlazar los datos correctamente.

Este paso es fundamental porque conecta el diseño teórico con la implementación práctica. Si el esquema relacional está bien construido, crear la base de datos en MySQL será un proceso lógico y sencillo.
Así termina la fase de diseño de una base de datos.
5. Normalización de bases de datos
Hasta ahora hemos aprendido a identificar entidades, atributos y relaciones, y a transformar ese diseño en un esquema relacional. Sin embargo, aunque una base de datos funcione, eso no significa que esté bien diseñada. La normalización nos ayuda a mejorar y depurar el diseño para evitar problemas futuros.
5.1. Problemas de redundancia y anomalías
Cuando una base de datos no está correctamente diseñada, suele aparecer un problema muy habitual: la redundancia de datos. Esto ocurre cuando la misma información se repite en varios lugares.
La redundancia provoca distintos tipos de anomalías. Por ejemplo, si un dato se repite y se actualiza solo en una parte, la información deja de ser coherente. También pueden aparecer problemas al insertar o eliminar datos, ya que una acción puede afectar involuntariamente a otros registros.
Nuestro objetivo con la normalización es reducir al mínimo estos problemas, organizando la información de forma más lógica.
5.2. Concepto de normalización
La normalización es un proceso que consiste en dividir y reorganizar las tablas de una base de datos siguiendo una serie de reglas llamadas formas normales. Estas reglas no son arbitrarias: están pensadas para garantizar que cada dato se almacene una sola vez y en el lugar adecuado.
Gracias a la normalización conseguimos bases de datos más limpias, fáciles de mantener y menos propensas a errores.
5.3. Primera forma normal
La primera forma normal establece que todos los atributos de una tabla deben contener valores atómicos, es decir, valores indivisibles. Esto significa que en una columna no debemos guardar listas ni conjuntos de datos.
Por ejemplo, en lugar de guardar varias asignaturas en un mismo campo, debemos crear registros independientes o tablas separadas. De este modo, cada celda de la tabla contiene un único valor claro y bien definido.
Esta tabla ALUMNO no cumple la 1FN:

Para normalizarla, podemos descomponer la información de forma que cada alumno–asignatura quede en una fila independiente:

Este principio nos obliga a estructurar mejor la información desde el principio y facilita enormemente las consultas posteriores.
5.4. Segunda forma normal
La segunda forma normal se centra en evitar dependencias incorrectas entre los datos. Una tabla cumple la segunda forma normal cuando todos sus atributos dependen completamente de la clave primaria.
En la práctica, esto implica que no debemos mezclar información de distintas entidades en una misma tabla. Si un dato no depende directamente del identificador principal, probablemente deba ir en otra tabla.
Este paso suele provocar que una tabla se divida en varias, cada una con una función clara. Aunque al principio pueda parecer más complejo, en realidad simplifica mucho la gestión de la base de datos.
Por ejemplo: si te fijas en la tabla anterior, la clave primaria sería (id_alumno, asignatura), ya que es la combinación de campos que no puede repetirse. Sin embargo, nombre y curso, son atributos que sólo dependen del alumno, no de la asignatura. Debemos dividir la tabla para aplicar la 2FN: por un lado tendremos la tabla que depende sólo de id_alumno, y por otro el resto de la información:
Tabla ALUMNO (PK: id_alumno):

Tabla ALUMNO_ASIGNATURA (PK: id_alumno, asignatura):

6. Introducción al lenguaje SQL
Comenzamos a trabajar con la herramienta que nos permitirá comunicarnos directamente con la base de datos. Hasta ahora hemos analizado, diseñado y organizado la información a nivel conceptual. A partir de aquí damos el salto a la parte práctica, aprendiendo el lenguaje que utilizan los sistemas gestores de bases de datos para crear y manipular información: SQL.
6.1. ¿Para qué sirve SQL?
SQL son las siglas de Structured Query Language, que en español podemos traducir como lenguaje de consulta estructurado. Se trata de un lenguaje diseñado específicamente para trabajar con bases de datos relacionales.
Nuestro trabajo con SQL consistirá en escribir instrucciones para indicarle a MySQL -recuerda, nuestro sistema gestor de bases de datos- qué queremos hacer en cada momento: crear una base de datos, definir una tabla, insertar información o consultar datos concretos. MySQL interpreta esas instrucciones y actúa en consecuencia.
Es importante entender que SQL no es un lenguaje de programación general, como Python o Java. No se utiliza para crear algoritmos complejos, sino para gestionar datos de forma estructurada.
6.2. Primer contacto con sentencias SQL
Antes de entrar en detalle en cada comando, es importante familiarizarnos con algunas ideas básicas. SQL se escribe como texto, utiliza palabras clave en inglés y sigue una estructura bastante legible, incluso sin experiencia previa.
Un aspecto relevante es que SQL no distingue entre mayúsculas y minúsculas en las palabras clave, aunque por claridad y buenas prácticas solemos escribirlas en mayúsculas. Además, cada sentencia termina con un punto y coma, lo que indica a MySQL que la instrucción ha finalizado.
En los siguientes apartados iremos trabajando de forma progresiva los comandos CREATE, INSERT, SELECT, UPDATE y DELETE, viendo cómo el diseño que hemos realizado se convierte en acciones reales sobre una base de datos.
7. Creación de bases de datos y tablas con SQL
En este apartado empezamos a trabajar directamente con el lenguaje SQL. Todo lo que hemos diseñado en papel se va a convertir ahora en instrucciones reales que MySQL entiende y ejecuta. Nuestro objetivo no es memorizar comandos, sino entender qué hace cada uno y por qué se utiliza.
7.1. Creación de una base de datos
El primer paso es crear una base de datos. En SQL esto se hace con una instrucción muy clara, cuyo nombre ya indica su función.
Por ejemplo, si queremos crear una base de datos para gestionar información de un instituto, podemos escribir:

Al ejecutar esta sentencia, MySQL crea un nuevo contenedor llamado instituto, que será el espacio donde guardaremos nuestras tablas. En phpMyAdmin veremos inmediatamente cómo aparece la nueva base de datos en el panel lateral:

7.2. Selección de la base de datos de trabajo
Una vez creada la base de datos, debemos indicarle a MySQL que queremos trabajar sobre ella. Para ello usamos la instrucción USE.
USE instituto;
A partir de este momento, todas las tablas que creemos y todos los datos que insertemos estarán asociados a la base de datos instituto. Este paso es fundamental para evitar trabajar sobre la base de datos equivocada.
7.3. Creación y manipulación de tablas
Una vez creada la base de datos y seleccionada la base de datos con la que trabajaremos es hora de aprender a crear y modificar tablas.