Este documento es un complemento práctico a los contenidos teóricos que se cubren en el Tema 8 de TIC de 1º Bachillerato.
Tabla de contenidos
El Lenguaje de Manipulación de Datos (DML, por sus siglas en inglés) es un elemento indispensable de SQL utilizado para realizar operaciones sobre los datos almacenados en bases de datos.
El DML permite a los usuarios insertar, consultar, actualizar y eliminar datos en las tablas de la base de datos. Estas operaciones son fundamentales para el manejo de los datos, permitiendo a las aplicaciones y a los usuarios interactuar de manera efectiva con la base de datos.
Las principales instrucciones DML en SQL incluyen:
- INSERT: para insertar nuevos registros en una tabla.
- SELECT: para consultar y recuperar registros de una o varias tablas.
- UPDATE: para modificar los datos existentes en los registros de una tabla.
- DELETE: para eliminar registros de una tabla.
Lo que vamos a aprender, por tanto, en el resto de este documento es a realizar esas cuatro operaciones usando instrucciones SQL.
1. Inserción de datos
La instrucción INSERT de SQL se utiliza para añadir uno o más nuevos registros a una tabla en la base de datos. La sintaxis básica de INSERT permite especificar tanto las columnas a las que se van a insertar datos como los valores correspondientes para cada una de esas columnas:
INSERT INTO nombre_tabla (columna1, columna2, columna3, ...)
VALUES (valor1, valor2, valor3, ...);Por ejemplo, supongamos que tenemos una tabla empleados con las siguientes columnas: id, nombre, correo_electronico, y salario. Para insertar un nuevo empleado en esta tabla, usaríamos una instrucción como la siguiente:
INSERT INTO empleados (nombre, correo_electronico, salario)
VALUES ('Antonio García', 'agarcia201@proton.me', 28700);MySQL permite la inserción de múltiples registros en una sola instrucción INSERT proporcionando varios conjuntos de valores:
INSERT INTO empleados (nombre, correo_electronico, salario)
VALUES ('Ana Gómez', 'agomez@proton.me', 32000),
('Luis Molina', 'lmolina@proton.me', 28000);Esta capacidad de insertar múltiples registros a la vez puede mejorar significativamente la eficiencia de la inserción de datos, especialmente cuando se trata de inicializar una tabla con un gran volumen de datos.
2. Consulta de datos
Para explicar la sintaxis de la consulta de datos en SQL con SELECT y sus cláusulas asociadas, vamos a utilizar como referencia una tabla de ejemplo llamada libros:
- id: identificador único del libro (INT).
- titulo: título del libro (VARCHAR).
- autor: nombre del autor del libro (VARCHAR).
- año_publicacion: año en que el libro fue publicado (YEAR).
- genero: género literario del libro (VARCHAR).
- precio: precio del libro (DECIMAL).
Supongamos que la tabla libros tiene los siguientes registros para ilustrar nuestros ejemplos:
| id | titulo | autor | año_publicacion | genero | precio |
|---|---|---|---|---|---|
| 1 | Cien Años de Soledad | Gabriel García Márquez | 1967 | Novela | 25.00 |
| 2 | La Sombra del Viento | Carlos Ruiz Zafón | 2001 | Misterio | 19.90 |
| 3 | El Hobbit | J.R.R. Tolkien | 1937 | Fantasía | 22.50 |
| 4 | 1984 | George Orwell | 1949 | Ciencia ficción | 18.00 |
Para consultar todos los registros de la tabla libros:
SELECT * FROM libros;Este comando devuelve todos los campos de todos los registros en la tabla libros, o sea, la tabla completa.
2.1. Seleccionar campos específicos
Para seleccionar solo el titulo y autor de todos los libros:
SELECT titulo, autor FROM libros;2.2. Uso de la cláusula WHERE
El objetivo de la cláusula WHERE es filtrar registros, es decir, seleccionar sólo aquellos registros cuyos campos cumplen una determinada condición.
Lista de libros publicados después del año 1950:
SELECT * FROM libros
WHERE año_publicacion > 1950;2.3. Uso de la cláusula ORDER BY
Utilizamos esta cláusula para ordenar los registros de una consulta basándonos en un criterio establecido.
Ordenar los libros en por precio de más barato a más caro:
SELECT * FROM libros
ORDER BY precio ASC;Para invertir el orden, usaríamos DESC.
2.4. Uso de la cláusula LIMIT
Su utilidad radica en limitar el número de resultados a un número determinado de registros. Es muy útil cuando una consulta devuelve muchos registros y sólo necesitamos conocer un número limitado de ellos.
Dame los dos primeros libros alfabéticamente hablando:
SELECT * FROM libros
ORDER BY titulo ASC
LIMIT 2;2.5. Uso de la cláusula GROUP BY y funciones de agregación
La cláusula GROUP BY se utiliza para agrupar filas que tienen los mismos valores en columnas especificadas en conjuntos resumidos, como cuando se aplican funciones de agregación (COUNT(), MAX(), MIN(), SUM(), AVG(), etc.). Es especialmente útil para obtener resúmenes estadísticos de los datos almacenados en una base de datos.
Cuando se usa GROUP BY, SQL sigue estos pasos para procesar la consulta:
- Selección de las filas: primero, selecciona las filas de la tabla que cumplen con las condiciones especificadas en la cláusula WHERE (si se incluye una).
- Agrupación de las filas: luego, agrupa las filas que tienen el mismo valor en las columnas especificadas en GROUP BY.
- Aplicación de funciones de agregación: aplica las funciones de agregación a cada grupo.
- Selección de las filas resultantes: finalmente, devuelve una fila por grupo, con cualquier columna agregada incluida en los resultados.
SELECT column_name(s), aggregate_function(column_name)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);Considerando la tabla libros del ejemplo anterior, supongamos que queremos saber cuántos libros hay de cada género:
SELECT genero, COUNT(*) AS numero_de_libros
FROM libros
GROUP BY genero;Este comando agrupará los libros por género y contará el número de libros en cada grupo, devolviendo el género y el conteo correspondiente.
Usamos el modificador AS para crear un alias o renombrar una columna.
También puedes agrupar por más de una columna.
Por ejemplo, para contar los libros por género y año de publicación:
SELECT genero, año_publicacion, COUNT(*) AS numero_de_libros
FROM libros
GROUP BY genero, año_publicacion;Además, también podemos filtrar los grupos creados usando HAVING.
Por ejemplo, para encontrar géneros con más de 1 libro:
SELECT genero, COUNT(*) AS numero_de_libros
FROM libros
GROUP BY genero
HAVING COUNT(*) > 1;Algunos detalles adicionales que debes conocer:
- Las columnas que no están agrupadas o incluidas en funciones de agregación no pueden ser seleccionadas directamente en la lista de selección.
- GROUP BY puede ser combinado con otras cláusulas de SQL para realizar consultas complejas y obtener información detallada de los datos.
2.6. Otros operadores útiles
Estos operadores son herramientas muy útiles para mejorar el filtrado de datos en consultas SQL, permitiendo realizar búsquedas basadas en patrones, rangos de valores, listas de valores específicos, etc.
LIKE
El operador LIKE se utiliza para buscar un patrón específico en una columna.
Por ejemplo, para encontrar todos los libros cuyos títulos contienen la palabra “El“:
SELECT * FROM libros
WHERE titulo LIKE '%El%';
El símbolo % representa cero, uno o múltiples caracteres. Este ejemplo devuelve todos los registros donde el titulo contiene “El” en cualquier parte del texto.
BETWEEN
El operador BETWEEN se emplea para seleccionar valores dentro de un rango dado (incluidos los extremos).
Por ejemplo, para encontrar libros publicados entre 1950 y 2000:
SELECT * FROM libros
WHERE año_publicacion BETWEEN 1950 AND 2000;
IN / NOT IN
El operador IN permite especificar múltiples valores posibles para una columna. NOT IN es el complemento de IN y se usa para excluir específicamente los valores seleccionados. Veamos un par de ejemplos.
Seleccionar libros que están en los géneros ‘Novela’, ‘Fantasía’ o ‘Misterio’:
SELECT * FROM libros
WHERE genero IN ('Novela', 'Fantasía', 'Misterio');
Seleccionar los libros que no están en los géneros ‘Drama’ ni ‘Poesía’:
SELECT * FROM libros
WHERE genero NOT IN ('Drama', 'Poesía');
Queremos encontrar libros publicados entre 1900 y 2000, excluyendo los géneros ‘Drama’ y ‘Poesía’, y cuyo título contenga la palabra “La”:
SELECT * FROM libros
WHERE año_publicacion BETWEEN 1900 AND 2000
AND genero NOT IN ('Drama', 'Poesía')
AND titulo LIKE '%La%';
DISTINCT
El operador DISTINCT se utiliza para eliminar filas duplicadas en el conjunto de resultados de una consulta y solo devuelve filas únicas. Es especialmente útil cuando queremos obtener una lista de valores distintos en una o más columnas.
Obtener una lista de los distintos géneros de la tabla libros:
SELECT DISTINCT genero FROM libros;
Esta consulta elimina cualquier duplicado. Si, por ejemplo, hay varios libros de “Novela”, “Misterio” y “Fantasía”, cada uno de estos géneros aparecerá solo una vez en el resultado.
IS NULL
El operador IS NULL se emplea para encontrar filas donde la columna especificada no tiene un valor (es decir, es NULL). Es útil para identificar registros que carecen de información en campos específicos.
Identificar los libros que no tienen asignado un precio:
SELECT * FROM libros
WHERE precio IS NULL;
Conocer los diferentes autores que no tienen todos sus libros con un precio asignado:
SELECT DISTINCT autor FROM libros
WHERE id IN (
SELECT id FROM libros
WHERE precio IS NULL
);
Ejercicio 8.5 – DML I
Teniendo en cuenta los campos y registros de la tabla libro:
| id | titulo | autor | año_publicacion | genero | precio |
|---|---|---|---|---|---|
| 1 | Cien Años de Soledad | Gabriel García Márquez | 1967 | Novela | 25.00 |
| 2 | La Sombra del Viento | Carlos Ruiz Zafón | 2001 | Misterio | 19.90 |
| 3 | El Hobbit | J.R.R. Tolkien | 1937 | Fantasía | 22.50 |
| 4 | 1984 | George Orwell | 1949 | Ciencia ficción | 18.00 |
| 5 | El Código Da Vinci | Dan Brown | 2003 | Thriller | 15.00 |
| 6 | Orgullo y Prejuicio | Jane Austen | 1813 | Novela | 12.00 |
| 7 | Moby Dick | Herman Melville | 1851 | Aventura | 17.50 |
| 8 | La Divina Comedia | Dante Alighieri | 1320 | Poesía | 21.00 |
| 9 | Hamlet | William Shakespeare | 1603 | Drama | 14.00 |
| 10 | Don Quijote de la Mancha | Miguel de Cervantes | 1605 | Novela | 24.00 |
| 11 | Frankenstein | Mary Shelley | 1818 | Terror | 16.00 |
| 12 | La Guerra de los Mundos | H.G. Wells | 1898 | Ciencia ficción | 13.50 |
| 13 | Ulises | James Joyce | 1922 | Modernismo | 20.00 |
| 14 | La Metamorfosis | Franz Kafka | 1915 | Novela | 10.00 |
| 15 | En busca del tiempo perdido | Marcel Proust | 1913 | Novela | 18.50 |
| 16 | El Principito | Antoine de Saint-Exupéry | 1943 | Fantasía | 11.00 |
| 17 | Cumbres Borrascosas | Emily Brontë | 1847 | Drama | 14.50 |
| 18 | El Gran Gatsby | F. Scott Fitzgerald | 1925 | Novela | 15.50 |
| 19 | Lolita | Vladimir Nabokov | 1955 | Novela | 20.50 |
| 20 | Crimen y Castigo | Fiódor Dostoyevski | 1866 | Novela | 19.00 |
- 1. Elabora la instrucción SQL que crea esta tabla en tu base de datos.
- 2. Utiliza una única instrucción INSERT para insertar en tu tabla libro los 20 registros que aparecen en el ejercicio.
- 3. Crea las 10 consultas que te permiten satisfacer estos requisitos:
- Todos los registros de la tabla libros.
- Los títulos y autores de los libros publicados antes de 1900.
- Los libros de género ‘Novela’ ordenados por año de publicación de manera ascendente.
- Encuentra el número de libros por cada género.
- Consulta los libros con precio mayor a 18.00 y ordena los resultados por precio de forma descendente.
- Encuentra el precio promedio de los libros por género.
- Consulta los títulos de los libros junto con sus años de publicación que tienen ‘Novela’ en su género y cuyo precio sea inferior a 20.00.
- Obtén los 5 libros más recientes.
- Encuentra el libro más caro de cada género.
- Consulta los libros que no tienen ‘a’ en el título y cuyo año de publicación esté entre 1900 y 2000, excluyendo los géneros ‘Drama’ y ‘Poesía’.
Entrega: debes entregar un archivo .sql con todas las instrucciones.
3. Actualización y eliminación de datos
En el apartado anterior vimos cómo podemos crear una tabla e insertar datos para trabajar con ellos. Esa es solo la mitad del propósito central del lenguaje de manipulación de datos. La otra mitad se refiere a la actuaizción –UPDATE– y eliminación de datos –DELETE-.
En el apartado 8.4.2. del tema, hemos visto la sintaxis de las instrucciones necesarias para lograr actualizar y borrar datos de una tabla.
Basándote en esa sintaxis y la experiencia que ya tienes con SQL, se propone la realización del siguiente ejercicio.
Ejercicio 8.6 – DML II
Crea una base de datos llamada Youtube.
Luego crea la tabla reproducciones usando este comando:
CREATE TABLE reproducciones (
ID INT AUTO_INCREMENT PRIMARY KEY,
titulo VARCHAR(255),
propietario VARCHAR(100),
reproducciones BIGINT,
pais VARCHAR(50),
me_gusta BIGINT,
no_me_gusta BIGINT,
duracion INT
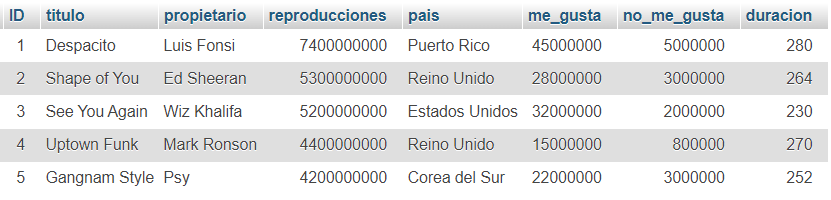
);A continuación, inserta 5 registros usando este comando:
INSERT INTO reproducciones (titulo, propietario, reproducciones, pais, me_gusta, no_me_gusta, duracion) VALUES
('Despacito', 'Luis Fonsi', 7400000000, 'Puerto Rico', 45000000, 5000000, 280),
('Shape of You', 'Ed Sheeran', 5300000000, 'Reino Unido', 28000000, 3000000, 264),
('See You Again', 'Wiz Khalifa', 5200000000, 'Estados Unidos', 32000000, 2000000, 230),
('Uptown Funk', 'Mark Ronson', 4400000000, 'Reino Unido', 15000000, 800000, 270),
('Gangnam Style', 'Psy', 4200000000, 'Corea del Sur', 22000000, 3000000, 252);Llegados a este punto, tu tabla debería tener este aspecto:
Elabora la instrucción SQL que resuelve cada una de estas necesidades.
- Actualizar el número de reproducciones del video ‘Despacito’ a 7500000000.
- Incrementar en un 10% el número de ‘me gusta’ para todos los videos.
- Cambiar el país de origen del video ‘Gangnam Style’ a ‘Corea del Sur – Seúl’.
- Disminuir en 200000 el número de ‘no me gusta’ para el video ‘Uptown Funk’.
- Actualizar la duración en segundos del video ‘Shape of You’ a 300 segundos.
- Eliminar el registro del video ‘See You Again’.
- Eliminar todos los videos con menos de 50000000 de ‘me gusta’.
- Eliminar todos los videos con duración superior a 260 segundos.
- Eliminar todos los videos del ‘Reino Unido’.
- Eliminar todos los videos que tengan más de 3000000 de ‘no me gusta’.
Entrega: debes entregar un archivo .sql con todas las instrucciones.