Currículo: esta unidad cubre parte de los saberes básicos del Bloque A – Desarrollo de Software (TICO.2.A.3) correspondiente a 2º Bachillerato. Además, se evalúan los criterios que puedes encontrar al final de esta página.
Tabla de contenidos
En este tercer tema del curso, avanzamos hacia el mundo del diseño de software y la resolución de problemas. Si recordáis, ya habéis adquirido una base sólida en programación y en ingeniería del software en los temas anteriores. Ahora, os enfrentaréis a un paso intermedio entre los temas 2 y 1.
El diseño de software no es solo una actividad técnica; es también un arte creativo donde cada decisión cuenta.
Pensad que sois como arquitectos de un gran edificio, donde cada línea de código es un ladrillo en esta construcción. Pero, ¿cómo empezar a construir? Aquí es donde entra en juego el enfoque Top-Down, una metodología que os permitirá ver el panorama completo antes de adentraros en los detalles.
La vida real está llena de problemas complejos.
Por ejemplo, pensemos en cómo las grandes empresas tecnológicas, como Google o Microsoft, descomponen sus proyectos enormes en partes más manejables. Este proceso se conoce como fragmentación de problemas, y es fundamental para abordar tareas complejas de forma eficiente.
Y ¿qué sería del diseño de software sin los patrones? Estos son como las técnicas de alta cocina para los programadores, ofreciendo soluciones probadas y efectivas a problemas comunes. Lo haremos a través de algoritmos bien conocidos, esos conjuntos de instrucciones paso a paso que son la esencia de cualquier programa.
¿Sabíais que el algoritmo de Google, conocido como PageRank, fue lo que catapultó a este buscador por encima de sus competidores a finales de los años 90?
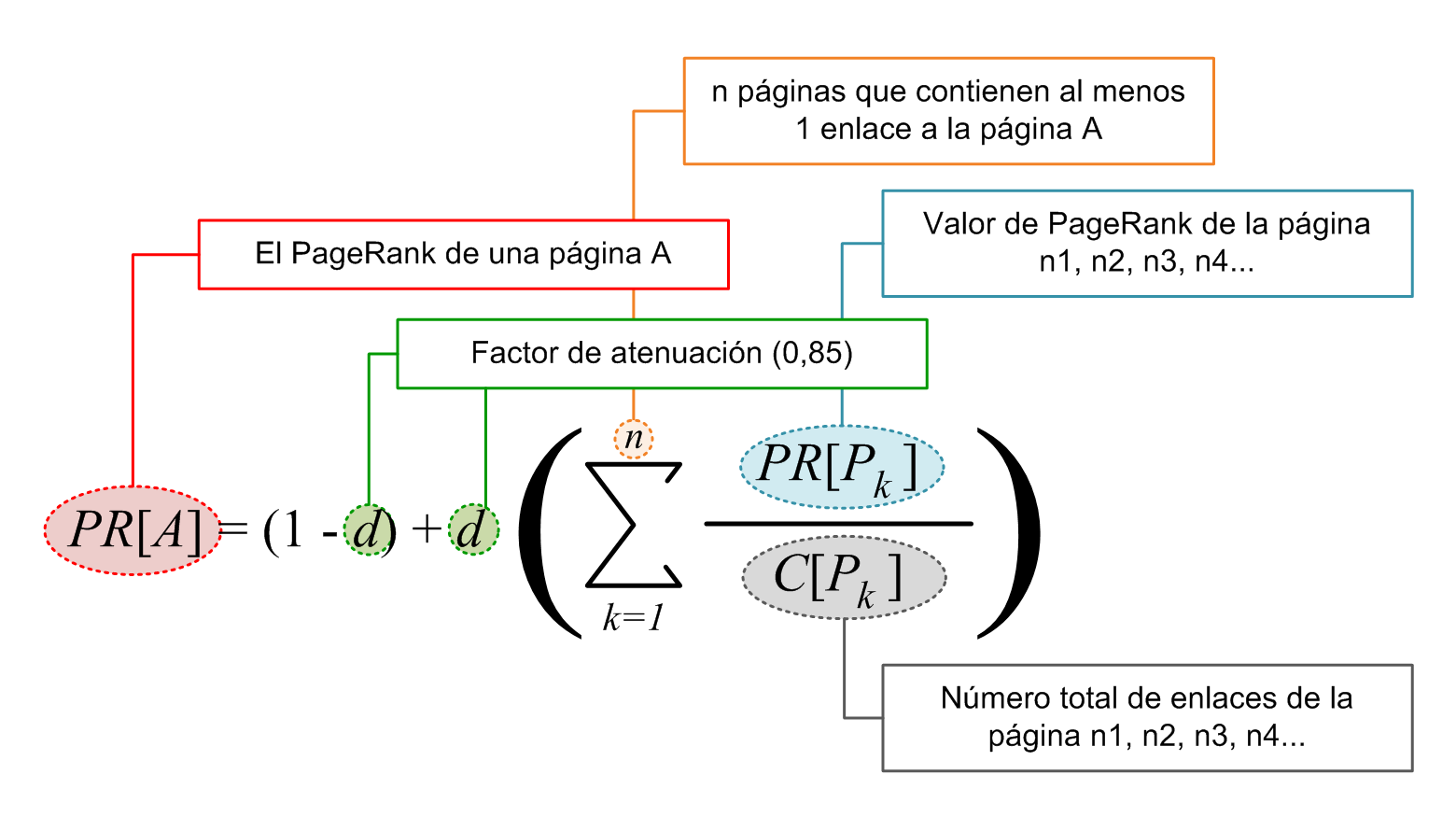
El pseudocódigo será vuestra herramienta para diseñar algoritmos de manera sencilla y comprensible, sin preocuparos por la sintaxis específica de un lenguaje de programación. Es como el boceto de un pintor antes de realizar su obra maestra.
Finalmente, aprenderéis sobre depuración –debugging-, un proceso fundamental para cualquier desarrollador.
Como anécdota, el término «bug» (error) en informática se popularizó cuando la pionera de la computación, Grace Hopper, encontró una polilla atrapada en un relé del ordenador Harvard Mark II en 1947.

3.1. Enfoque top-down
Para comenzar a explorar el enfoque top-down en el diseño de software, primero debemos entender qué significa este término.
Suponed que estáis frente a un complejo puzle. El enfoque top-down es como mirar primero la imagen completa en la caja para entender cómo encajan las piezas individuales. Luego situaríamos las piezas de los extremos. Luego buscaríamos cuáles tienen un lado plano, luego por las tonalidades agruparíamos la de cada lado y, finalmente, buscaríamos piezas con colores similares para ir completando las zonas más fáciles.

En el contexto del diseño de software, haríamos exactamente igual, empezaríamos por una visión global del sistema para luego ir desglosándolo gradualmente en componentes más pequeños y manejables, que también iremos detallando y desarrollando por separado. Este proceso se repite hasta que se alcanza el nivel de los componentes individuales.
Veamos un par de ejemplos donde podemos clarificar el concepto top-down:
Desarrollo de una aplicación web.
Al construir una aplicación web, primero se define su funcionalidad general y su interfaz de usuario. Luego, se diseña cada página y las interacciones entre ellas y, finalmente, se programan los elementos individuales como formularios o botones.
Creación de un videojuego.
Al desarrollar un videojuego, primero se establece la idea general y la historia. Posteriormente, se trabajan los niveles o misiones, y finalmente se detallan los elementos como escenarios, personajes, objetos y mecánicas de juego.
Como puedes ver, en ambos casos hemos diseñado dos aplicaciones con solo tres niveles de especialización, pero en la práctica esto supone una cantidad de iteraciones mucho más elevada. Por ejemplo, en el caso del videojuego, la última fase no acaba diseñando el personaje, sino que continúan desgranándose detalles como el movimiento de las articulaciones, cómo ondea el pelo o como mira en distintas posiciones.
Esta manera de diseñar aplicaciones tiene algunas ventajas, pero también algunos inconvenientes. Los dos más importantes son:
| PROS | CONTRAS |
| Facilita la organización: al tener una visión global, es más fácil organizar los recursos y planificar el desarrollo. | Dependencia de una buena planificación inicial: si la visión global no es clara o está mal definida, puede llevar a problemas en las fases posteriores. |
| Ayuda en la identificación de problemas: los problemas importantes se identifican pronto, evitando sorpresas en etapas avanzadas del desarrollo. | Riesgo de perder detalle: al centrarse en el panorama general, a veces se pueden pasar por alto detalles importantes en los componentes más pequeños. |
El enfoque top-down fue clave en el desarrollo de sistemas operativos como Windows o Linux. Esto permitió a sus creadores visualizar la estructura general del sistema operativo antes de sumergirse en la programación de sus múltiples componentes.
Ejemplo práctico
Supongamos que tenemos que diseñar el esquema básico de un sistema de video en streaming al estilo de Netflix, aplicando el enfoque top-down. Este sistema debe permitir a los usuarios buscar y ver contenido, crear listas de reproducción y recibir recomendaciones personalizadas. Debemos considerar los siguientes componentes principales:
- Interfaz de usuario.
- Gestión de contenidos.
- Sistema de recomendaciones.
- Base de datos de usuarios.
- Reproductor de video.
Teniendo en cuenta todo lo anterior, vamos a ver cómo podrían ser los tres primeros niveles de desglose aplicando el enfoque que estamos estudiando.
Nivel 1. Visión global del sistema.
El sistema debe proporcionar una plataforma de streaming de video accesible y fácil de usar, con una amplia gama de contenido.
Nivel 2. Desglose de componentes principales.
- Interfaz de usuario:
- Debe ser intuitiva y atractiva.
- Incluye elementos como menús, barras de búsqueda y vistas de contenido.
- Gestión de contenidos:
- Sistema para almacenar y clasificar películas, series y documentales.
- Funcionalidades para añadir, eliminar o modificar contenido.
- Sistema de recomendaciones:
- Algoritmo que sugiere contenido basado en el historial de visualización del usuario y preferencias.
- Base de datos de usuarios:
- Almacena información del usuario como preferencias, historial de visualización y configuraciones de cuenta.
- Reproductor de video:
- Debe soportar diferentes formatos y calidades de vídeo.
- Incluye controles básicos como play, pausa, adelantar y retroceder.
Nivel 3. Detalle de componentes individuales.
- Interfaz de usuario:
- Diseño de la página principal, página de perfil y página de configuraciones.
- Implementación de funciones de búsqueda y filtros.
- Gestión de contenidos:
- Crear una base de datos para el almacenamiento de contenido.
- Desarrollar un panel de administración para la gestión del contenido.
- Sistema de recomendaciones:
- Desarrollar un algoritmo basado en inteligencia artificial para personalizar las recomendaciones.
- Integrar el sistema con la base de datos de usuarios y el historial de visualización.
- Base de datos de usuarios:
- Diseño de la estructura de la base de datos.
- Implementación de medidas de seguridad para proteger los datos del usuario.
- Reproductor de video:
- Integrar un reproductor de video compatible con múltiples dispositivos.
- Añadir características como subtítulos, selección de idioma y control de calidad de video.
Confío en que este ejercicio te haya ayudado a comprender cómo se estructura y planifica un sistema de software complejo. Recuerda, que aquí no acaba el trabajo, sino que se sucederían más niveles de especialización hasta llegar a los detalles más pequeños del sistema.
3.2. Patrones de diseño
Visualízate en una empresa de desarrollo de software. El año pasado participaste en un proyecto encargado de desarrollar una web dedicada a la venta de ropa de segunda mano. Este año, empezaste participando en otro proyecto dedicado a canjear cupones de descuento. Y ahora, se está cerrando otro proyecto, cuyo objetivo es intercambiar objetos que ya no necesitamos.
¿Cómo crees que tu empresa va a abordar el desarrollo de estos tres proyectos? ¿Desarrollará el código de la aplicación desde cero en cada uno de los tres? ¿Analizará y diseñará una gestión de datos nueva para cada uno? Nada de eso. Buscará qué tiene en común cada nuevo proyecto con todo lo que ha hecho la empresa anteriormente. Analizará cada aplicación intentando buscar nexos de unión, para reutilizar todo lo posible el trabajo que ya se hizo, minimizando así los costes de desarrollo.
Si te fijas, los tres proyectos indicados tienen muchas cosas en común. Comprar, canjear cupones o cambiar objetos, son muy parecidos, no son más que un intercambio -por dinero, por descuento o por otro objeto, respectivamente-. Por tanto, el diseño estructural de los tres proyectos va a ser muy parecido.
Aquí es donde surge la utilidad de los patrones de diseño.
Los patrones de diseño en el mundo del software son soluciones típicas a problemas comunes. Son como «plantillas» que se pueden aplicar en diferentes situaciones para resolver problemas de diseño similares. Los patrones están formados por un conjunto de prácticas probadas que se han desarrollado a lo largo de los años. Estos patrones ofrecen un marco estandarizado para resolver problemas de diseño complejos de una manera eficiente.
Veamos un ejemplo práctico utilizando el patrón de diseño Factory.
El patrón de diseño «Factoría» es uno de los más sencillos y populares, especialmente útil para comprender la programación orientada a objetos. Este patrón se utiliza para crear objetos sin especificar la clase exacta del objeto que se creará. Es ideal para situaciones en las que se debe crear uno de varios posibles subtipos de una clase, en función de los datos de entrada.
Supongamos que estamos desarrollando un programa para una empresa que fabrica dispositivos electrónicos como teléfonos, tabletas y ordenadores. Cada tipo de dispositivo tiene características diferentes, pero todos comparten ciertas operaciones básicas como encender, apagar y reiniciar.
1. Definición de la interfaz común
Primero, definiremos la interfaz común para los dispositivos. En Python, esto se hace mediante una clase base con métodos que las subclases deben implementar:

2. Creación de subclases concretas
Ahora, creamos subclases para cada tipo de dispositivo:

3. Creación de la clase Factory
A continuación, implementamos la clase Factoría que crea instancias de los dispositivos:
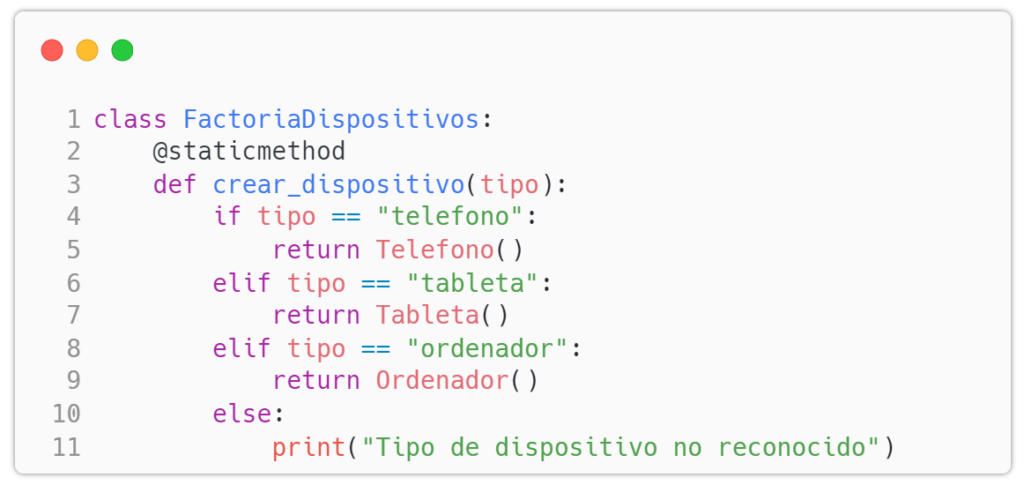
4. Uso del patrón Factory
Finalmente, un cliente del programa puede utilizar la factoría para obtener instancias de dispositivos:
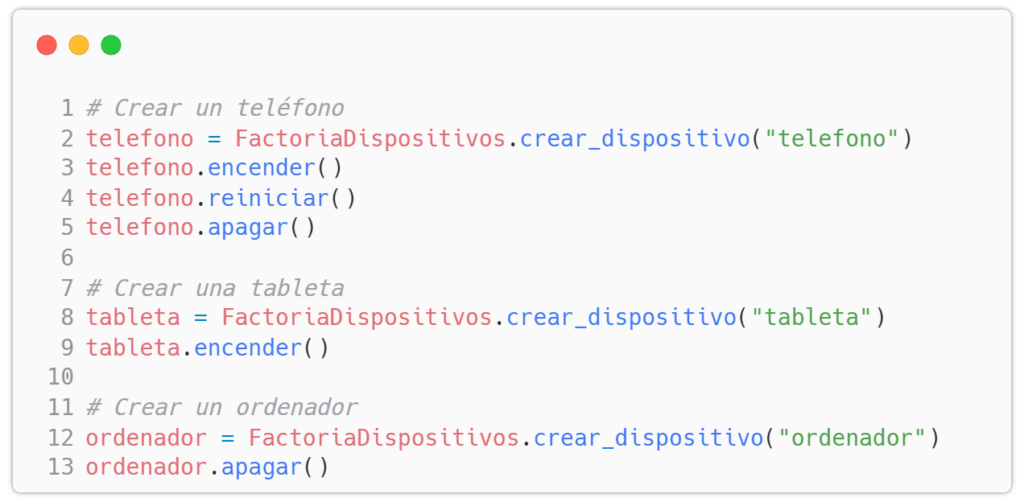
En este código, la clase FactoriaDispositivos decide qué tipo de dispositivo crear basándose en el parámetro de entrada. El cliente trabaja con los dispositivos a través de su interfaz común, lo que permite un código flexible y fácilmente extensible.
Así, tenemos patrones de diseño populares como los siguientes, explicados en una terminología más alejada de la programación para que se entienda su utilidad:
- Singleton: supongamos que tienes un diario personal y quieres que solo exista una copia de él. El patrón Singleton asegura que solo se pueda crear una única copia de una clase (como tu diario) en todo el programa, evitando que existan duplicados.
- Observador: es como tener un sistema de notificaciones. Si algo importante ocurre (como recibir un mensaje), el patrón Observador se asegura de que todas las partes interesadas en ese evento (como tus amigos o aplicaciones) sean informadas automáticamente.
- Fachada: es como el mostrador de información en un gran centro comercial. El patrón Fachada proporciona una forma sencilla de acceder a un sistema complejo (el centro comercial) mediante una interfaz simple y clara (el mostrador de información), ocultando la complejidad detrás.
- Estrategia: ponte en el caso de que tenga diferentes estrategias para llegar a un concierto (como caminar, coger un autobús o ir en metro). El patrón Estrategia te permite cambiar fácilmente entre estos planes sin alterar el objetivo final, que es llegar a la escuela.
3.3. Algoritmos
Como ya sabes, un algoritmo es una serie de pasos estructurados para realizar una tarea o resolver un problema. Sin embargo, es necesario ahondar un poco más en su complejidad para entender mejor su enorme importancia.
Un buen algoritmo resuelve un problema no solo de manera correcta, sino también de manera eficiente, utilizando la menor cantidad de recursos posibles, como tiempo y memoria. Y esto, no es tan fácil como simplemente escribir un algoritmo. De hecho, es uno de los campos de la informática más complejos que existen.
Vamos a ver un ejemplo, de las enormes diferencias en cuanto a eficiencia, utilizando dos versiones de un algoritmo que resuelve el mismo problema: encontrar el número máximo en una lista de números. Esta tarea es tremendamente común: se utiliza para saber por ejemplo quién es el usuario con más seguidores, con más publicaciones, con más tiempo de permanencia, con más visualizaciones, con más likes, …. Es decir, se trata de un algoritmo que se ejecuta diariamente millones de veces. Por tanto, un pequeño ahorro en el tiempo de ejecución cada vez que se usa, proporciona un ahorro ingente de recursos a nuestro sistema.
Presentaremos, como decía, dos versiones una menos eficiente y otra más eficiente. Luego, explicaré por qué la segunda es superior en términos de eficiencia -recuerda, queremos encontrar el número máximo en una lista de números-.
Versión menos eficiente: algoritmo de comparación doble

- Comenzamos verificando si la lista está vacía. Si lo está, imprimimos un mensaje y terminamos el programa.
- Luego, recorremos la lista con dos bucles anidados. El bucle externo (i) recorre cada elemento, y el bucle interno (j) compara el elemento i con todos los elementos siguientes.
- Si encontramos un elemento en el bucle interno que es mayor que el elemento i, sabemos que el elemento i no puede ser el máximo, así que continuamos con el siguiente elemento i.
- Si terminamos el bucle interno sin encontrar un elemento mayor, significa que el elemento actual i es el máximo, así que lo imprimimos y terminamos el programa.
Versión más eficiente: algoritmo de recorrido único

Este algoritmo recorre la lista una sola vez, empezamos asumiendo que el primer elemento es el máximo y luego comparamos cada elemento siguiente con este máximo actual. Si encontramos uno más grande, actualizamos el máximo. Al final, imprimimos el máximo que encontramos.
¿Cuál es la diferencia en términos de eficiencia entre ellos?
En la versión menos eficiente, se realiza una comparación para cada par de elementos en la lista, lo que conduce a un número total de comparaciones igual a n2 en el peor caso. Esto significa que el tiempo que tarda en ejecutarse aumenta cuadráticamente a medida que aumenta el tamaño de la entrada -la cantidad de elementos de la lista-.
En la versión eficiente, se compara cada elemento de la lista solo una vez con el máximo actual, resultando en n−1 comparaciones en total. Es decir, el tiempo de ejecución aumenta linealmente con el tamaño de la entrada, siendo mucho más eficiente para listas grandes.
En resumen, el segundo algoritmo es más eficiente ya que reduce significativamente el número de comparaciones necesarias, lo que se traduce en un menor tiempo de ejecución, especialmente notorio cuando la lista es grande.
Como ves, el diseño de algoritmos no es una tarea nada sencilla, aunque maestros de la computación como Dijkstra elevaron esta ciencia a categoría de arte.
Y tenía toda la razón del mundo, puesto que encontrar un algoritmo más eficiente que otro, no tiene tanto que ver con los conocimientos en computación, sino con la creatividad de los programadores.
Si tienes curiosidad, en este sitio web, tienes una enorme cantidad de algoritmos muy conocidos, explicados de manera sencilla y gráficamente para ayudarte a entender cómo funciona:
3.4. Pseudocódigo
El pseudocódigo es una herramienta muy útil en las etapas iniciales de diseño de algoritmos. No es un lenguaje de programación real, sino más bien una manera simplificada y legible de describir los pasos que un algoritmo debe seguir para realizar una tarea. Utiliza una combinación de lenguaje natural y una estructura similar a la de los lenguajes de programación para describir algoritmos. Su propósito es expresar la lógica de un algoritmo de manera clara y comprensible, sin preocuparse por la sintaxis específica de un lenguaje de programación.
En los dos algoritmos del apartado anterior tienes dos ejemplos de cómo se expresan.
Al ser independiente de los lenguajes de programación, puede ser entendido por personas con conocimientos en diferentes tecnologías: un experto en Java, un analista de Python o un desarrollador en PHP. Por eso, es una herramienta útil para comunicar ideas y algoritmos entre distintos miembros de un equipo especializados en diferentes lenguajes de programación.
En los primeros días de la computación, antes de que los lenguajes de programación estuvieran ampliamente desarrollados, los algoritmos a menudo se describían en forma de pseudocódigo. Además, en el campo de la educación ha sido utilizado ampliamente para enseñar conceptos de programación a estudiantes sin la necesidad de aprender primero la sintaxis de un lenguaje de programación específico.
Para que veas un ejemplo de lo que implica, aquí tienes un programa en pseudocódigo que suma los N primeros números naturales. Luego, podrás ver la misma versión del programa en cuatro lenguajes muy populares: Python, Java, PHP y C++.
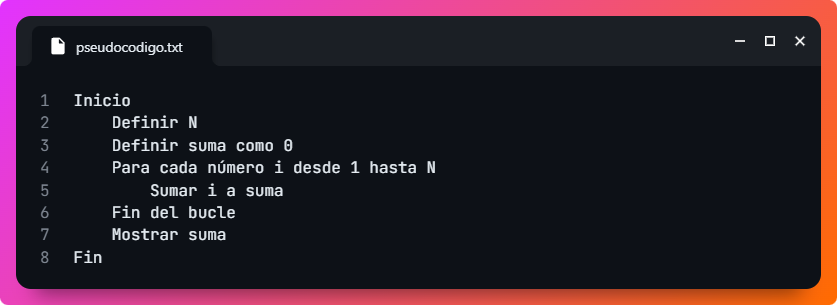
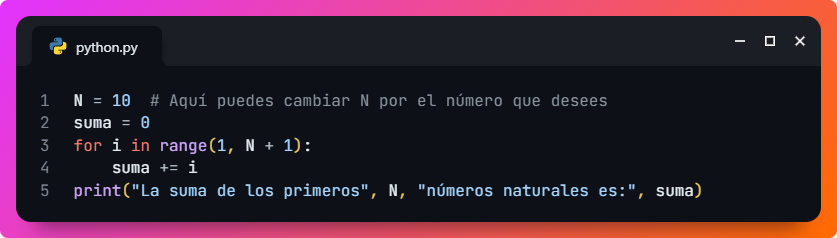
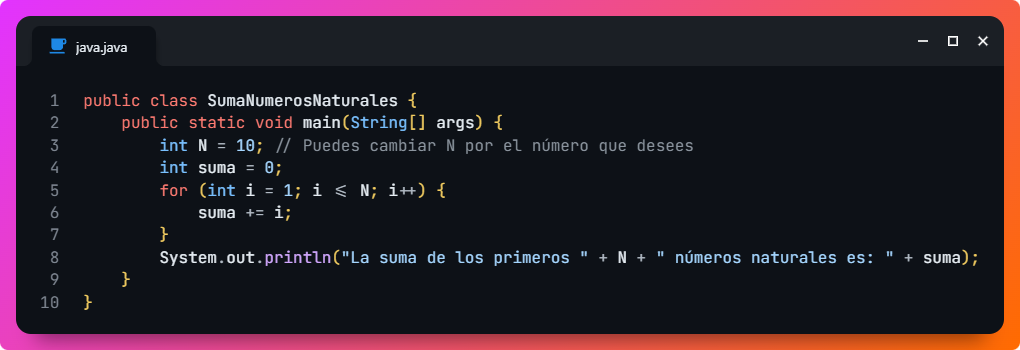


Si te fijas, la estructura de las cuatro versiones son prácticamente idénticas, salvo las particularidades de sintaxis de cada lenguaje de programación concreto. De esta manera, podemos definir a grandes rasgos nuestro código, discutirlo entre todos los especialistas y luego traducirlo o adaptarlo al lenguaje de programación que finalmente se elija según los criterios aplicables en cada proyecto.
En este video puedes encontrar varios ejemplos sencillos donde se explica cómo escribir pseudocódigo con las instrucciones más comunes:
3.5. Depuración
Una vez que hemos diseñado el código de nuestra aplicación, probablemente utilizando pseudocódigo en algunas partes más problemáticas, es la hora de implementar nuestro programa utilizando el lenguaje de programación elegido.
En esta parte del desarrollo de la aplicación, es fundamental encontrar y corregir errores -bugs- en el código. De ello se encarga la depuración o «debugging». Un proceso efectivo de depuración asegura que el software sea confiable, eficiente y libre de fallos que puedan afectar su funcionamiento.
La depuración implica examinar el código, identificar dónde y por qué ocurren los errores, y corregirlos. Es como ser un detective en el mundo de la programación: se buscan pistas (errores), se analizan las causas (el porqué de los errores) y se resuelven los problemas (se corrigen los errores).
En muchas de las etapas del proceso de desarrollo de software podemos aplicar técnicas de depuración, aunque las más comunes son las que se aplican en la fase de implementación.
(1) En el mejor de los casos, sabremos que nuestro código presenta errores porque el propio entorno de desarrollo -IDE, como PyCharm- nos lo va a marcar con llamativos mensajes en rojo, son los errores de sintaxis.
(2) En otras ocasiones, sabremos que nuestro programa contiene errores, porque a pesar de que el entorno de desarrollo no nos muestra errores de sintaxis, lo que obtenemos no tiene sentido o no son datos coherentes. Inicialmente no sabemos donde está el error, pero sabemos que algo no está funcionando correctamente.
(3) Pero, sin duda, los errores más temibles para todos los programadores, son los llamados errores intermitentes. Son aquellos que no se producen en cada ejecución del programa, sino sólo bajo ciertas condiciones especiales. Encontrar estos últimos es una tarea tediosa que consume mucho tiempo y esfuerzo, por eso es fundamental ir realizando pruebas a nuestro código para intentar minimizarlos.
Como hemos avanzado, casi todos los IDE incorporan ya funciones para la depuración. El módulo de nuestro entorno de desarrollo encargado de esta tarea se llama «debugger».
En PyCharm, podemos acceder a las herramientas de depuración con el icono del «bicho» -bug- (situado en la parte superior derecha del programa):
Cuando pulsamos en la ejecución del programa en modo depuración, se activan comprobaciones adicionales que nos permiten comprobar si todo va bien. Pero, ciertos errores o inconsistencias no serán detectados, por lo que deberemos hacer una ejecución manual paso a paso.
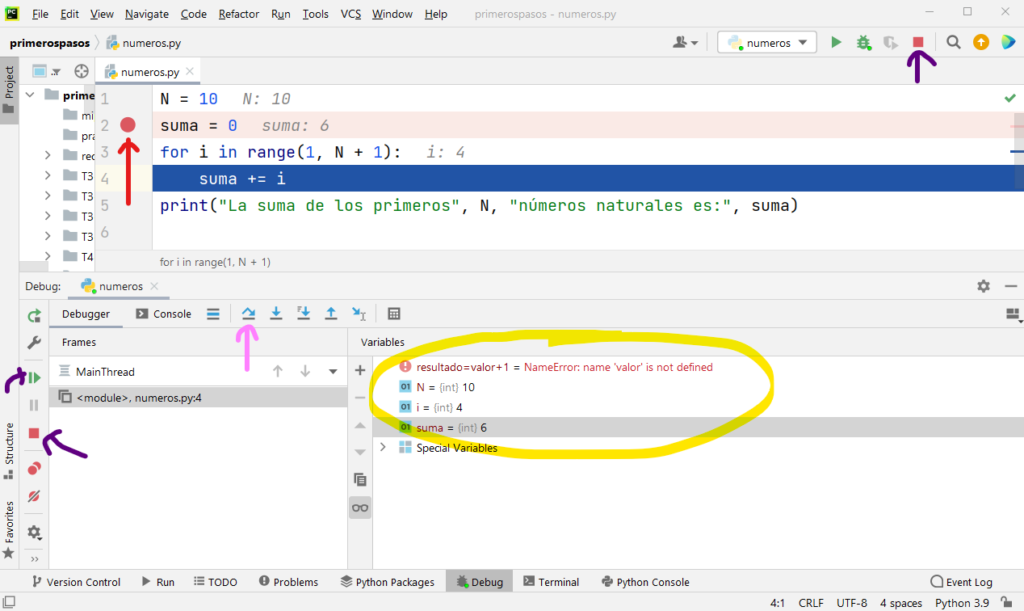
Una buena manera de hacerlo es situar un «breakpoint» o punto de ruptura. Se trata de marcar una línea de código donde queremos que se pare la ejecución del programa. Esto lo hacemos pulsando con el ratón junto al número de línea que queremos marcar (aparecerá un punto rojo). Observa la línea de código número 2 de la imagen.
Una vez marcadas las líneas donde queremos que el programa pare, lo ejecutamos en modo depuración. El programa comenzará a ejecutarse y se parará en cada breakpoint. Para avanzar podemos utilizar una variedad de iconos disponibles. El primero de ellos -señalado con flecha rosa- nos permite avanzar línea a línea. Es decir, cada vez que lo pulsemos el programa ejecutará la siguiente instrucción prevista en nuestro código.
Las flechas moradas indican los botones que podemos pulsar si queremos parar la ejecución o terminarla hasta el final. Si queremos que termine, debemos retirar los breakpoints.
Pero, la zona más importante de todas, es la que aparece rodeada de amarillo, el inspector de variables. En esta zona, veremos cómo aparecen los nombres de las variables y otras estructuras de datos «visibles» en ese momento de la ejecución, y los valores que tienen en ese punto. Así, conforme vamos ejecutando manualmente nuestro programa paso a paso, podemos ir comprobando si los valores que van recogiendo las variables son los correctos o no.
Estas herramientas de depuración -y la ejecución paso a paso de programas-, no son solo útiles para detectar errores o corregir inconsistencias, sino que son una excelente manera de entender la ejecución de los programas.
Cuando llega a nuestras manos un algoritmo, a primera vista complejo, podemos desentrañar todos sus misterios haciéndole una ejecución paso a paso con el depurador para ver cómo funciona.
Como siempre, debemos recordar, que el proceso de desarrollo de software es una tarea realmente compleja. Cuando tenemos un programa con miles de líneas de código distribuidas en cientos de archivos interrelacionados, encontrar un error, aunque sea utilizando un depurador es un trabajo realmente complejo que suele consumir una cantidad ingente de recursos tanto en tiempo como en costes económicos.
Por eso, siempre es una regla de oro, seguir las recomendaciones, las buenas prácticas, los patrones de diseño y todos aquellos protocolos probados que nos previenen de la mayor parte de los errores que dan al traste con el éxito de nuestros proyectos.
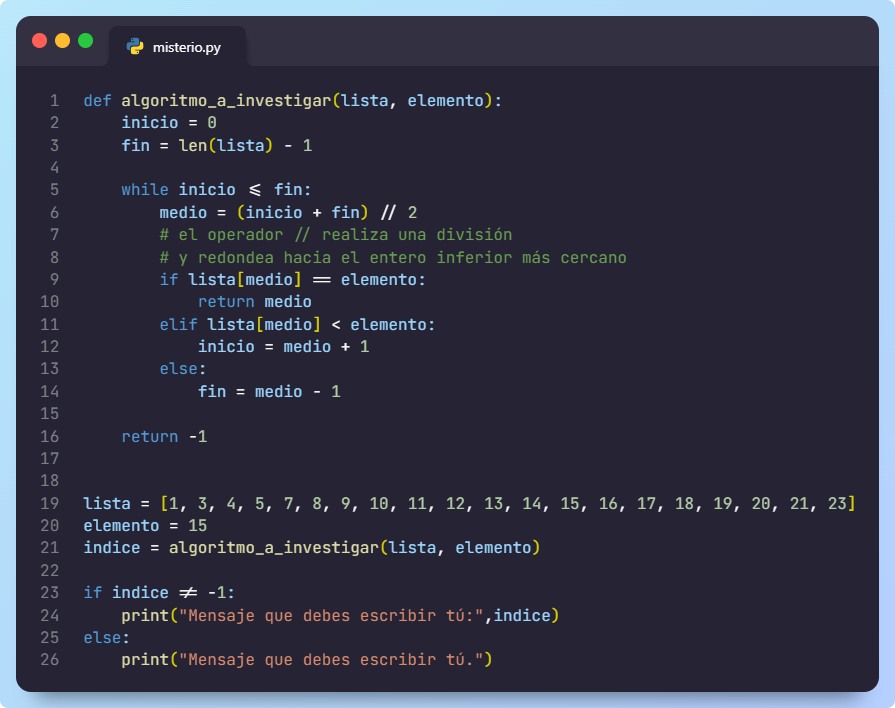
Ejercicio 3.1 – ¿Qué hace este algoritmo?
El algoritmo que aparece aquí abajo, es muy popular. Resuelve un problema muy común en el día a día de los programadores. Y, aunque no es el método más eficiente para hacer lo que hace, se suele usar para compararlo con otros métodos. Pero esa, es una tarea que dejamos para la universidad.
Tu trabajo es leer el código, llevártelo a tu IDE y apoyándote en la ejecución paso a paso que te permite el depurador, descubrir qué problema resuelve el algoritmo.
Cuando lo tengas claro, crea un documento de Google Docs y escribe qué hace cada línea del programa. Además, elige un nombre apropiado para la función y define qué pondrías en cada uno de los dos mensajes que aparecen en las líneas 24 y 26.
Entrega: debes entregar un enlace público de Google Docs antes de la fecha límite indicada en classroom.